1. AIOps是什么?
运维的发展,经历了手工运维、自动化运维、DevOps、AIOps。
Gartner公司2013提出ITOA(IT Operations Analytics),2016年将ITOA概念升级为AIOps(Algorithmic IT Operations),2017年发现AI越来越火,于是把AIOps重新定义为Artificial Intelligence for IT Operations,也就是智能运维。
AIOps将人工智能应用于运维领域,基于已有的运维数据(日志、监控信息、应用信息等),通过机器学习的方式来进一步解决自动化运维没办法解决的问题。
AIOps的目标是,利用大数据、机器学习和其他分析技术,通过预防预测、个性化和动态分析,直接和间接增强IT业务的相关技术能力,实现所维护产品或服务的更高质量、合理成本及高效支撑。
2. AIOps做什么?
2.1. 知识领域
AIOps涉及到行业领域知识、运维场景领域知识和机器学习领域知识,如下图: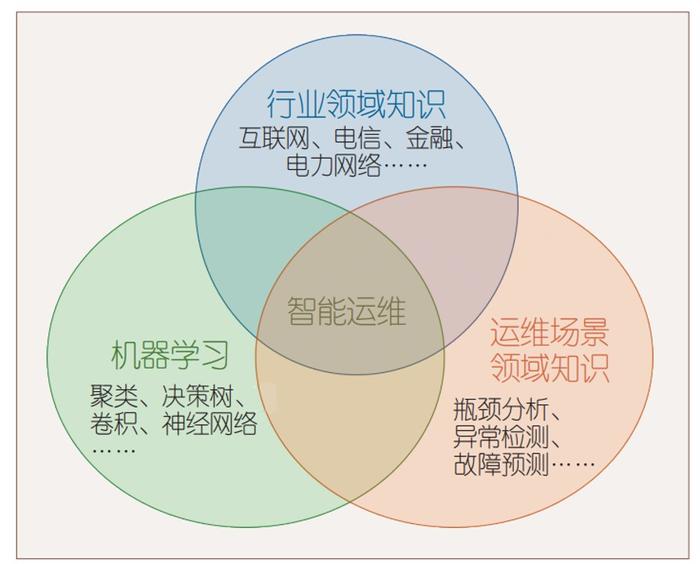
2.2. 团队构成
一个AIOps团队,要有运维工程师、运维开发工程师、运维AI工程师,如下图: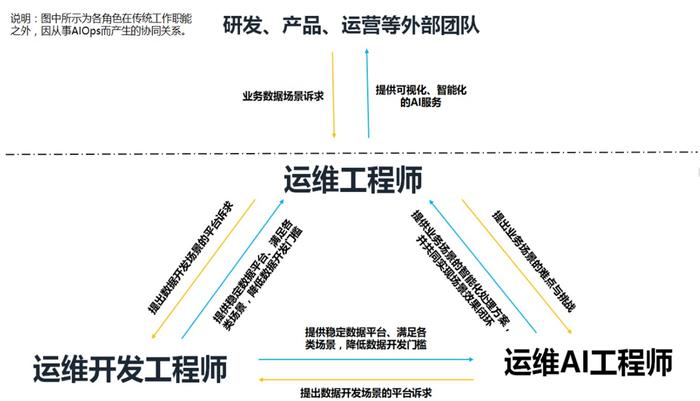
2.3. 研究方向
研究方向按照时间来分,可以分为针对历史事件、针对当前事件、针对未来事件,如下图: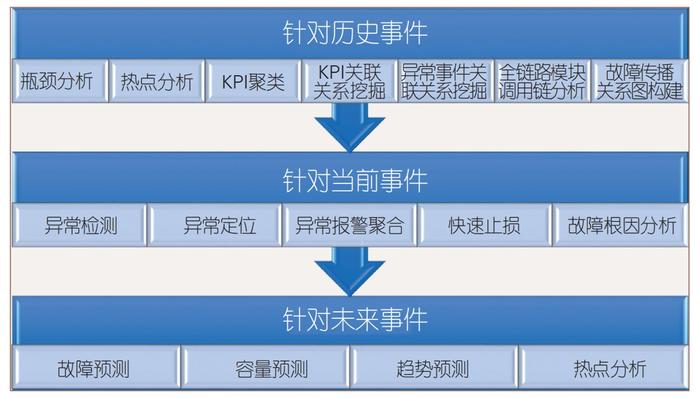
研究方向按照应用场景来分,可以分为效率提升、质量保障、成本管理,如下图:
3. AIOps平台
3.1. 能力分级
AIOps 的建设可以先由无到局部单点探索、再到单点能力完善,形成解决某个局部问题的运维AI“学件” ,再由多个具有 AI 能力的单运维能力点组合成一个智能运维流程。AIOps 能力分级可具体可᧿述为5级,如下图:
- 开始尝试应用AI能力,还无较成熟单点应用
- 具备单场景的AI运维能力,可以初步形成供内部使用的学件
- 有由多个单场景AI运维模块串联起来的流程化AI运维能力,可以对外提供可靠的运维AI学件
- 主要运维场景均已实现流程化免干预AI运维能力,可以对外提供可靠的AIOps服务。
- 有核心中枢AI,可以在成本、质量、效率间从容调整,达到业务不同生命周期对三个方面不同的指标要求,可实现多目标下的最优或按需最优。
“学件”(Learnware)一词由南京大学周志华老师原创,学件=模型+规约。
学件,亦称AI运维组件,类似程序中的API或公共库,但API及公共库不含具体业务数据,只是某种算法,而 AI 运维组件(或称学件),则是在类似API的基础上,兼具对某个运维场景智能化解决的“记忆”能力,将处理这个场景的智能规则保存在了这个组件中。
这个智能规则是在一定量的数据下学习而来的,且具有“可重用” 、“可演进”、“可了解”的特性,既可共享由专家利用数据训练的算法,又可保护数据和隐私。
3.2. 能力框架
基于上述 AIOps 能力分级, 对应的 AIOps 能力框架如下。
3.3. 能力体系
AIOps工作平台能力体系主要功能是为AIOps的实际场景建设落地而提供功能的工具或者产
品平台,其主要目的是降低AIOps的开发人员成本,提升开发效率,规范工作交付质量。 AIOps平台功能与一般的机器学习(或者数据挖掘)平台极为类似,此类产品国外的比如Google的AutoML。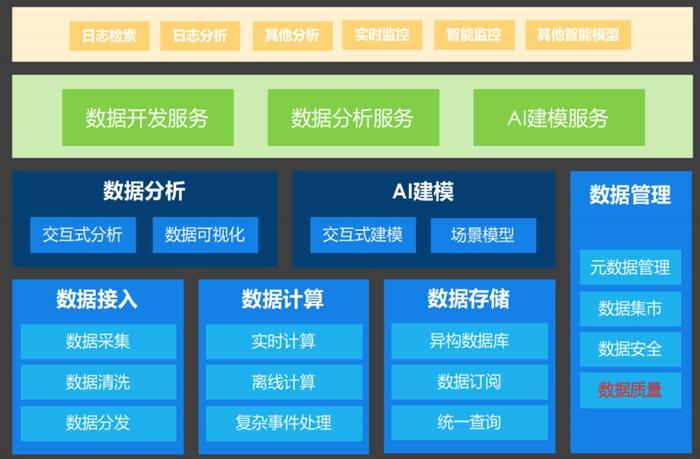
3.4. 平台要素
AIOps平台从底层到上层应该包含如下要素: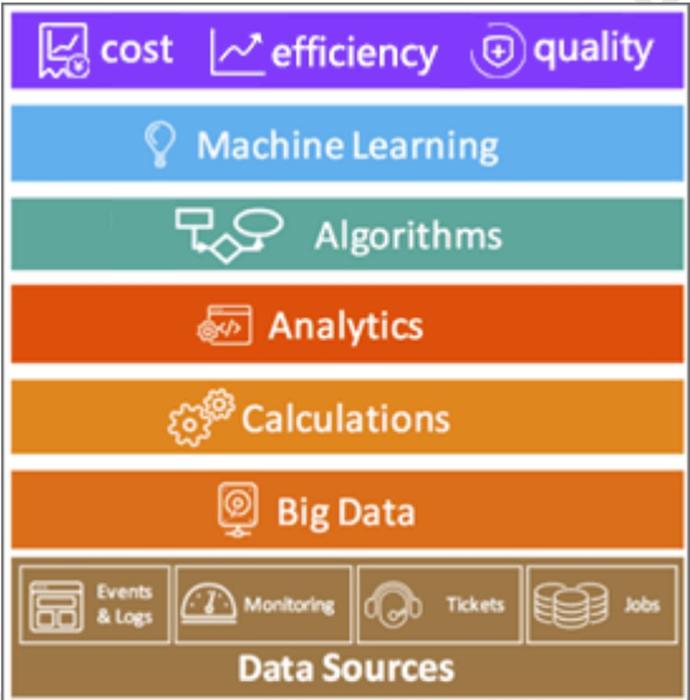
- 数据源:大量并且种类繁多的 IT 基础设施
- 大数据平台:用于处理历史和实时的数据
- 计算与分析:通过已有的 IT 数据产生新的数据,例如数据清洗、去除噪声等
- 算法:用于计算和分析,以产生 IT 运维场景所需要的结果
- 机器学习:这里一般指无监督学习,可根据基于算法的分析结果来产生新的算法
4. AIOps关键技术
4.1. 数据采集
数据采集负责将智能运维所需要的数据接入至AIOps平台,所接入的运维数据类型一般包括(但不限于)日志数据,性能指标数据,网络抓包数据,用户行为数据,告警数据,配置管理数据,运维流程类数据等。
数据采集方式可分为无代理采集以及有代理采集两种。其中无代理采集为服务端采集,支持SNMP、数据库JDBC、TCP/UDP监听、SYSLOG、Web Service,消息队列采集等主流采集方式。有代理采集则用于本地文件或目录采集,容器编排环境采集,以及脚本采集等。
4.2. 数据处理
- 数据字段提取:通过正则解析,KV解析,分隔符解析等解析方式提取字段
- 规范化数据格式:对字段值类型重定义和格式转换
- 数据字段内容替换:基于业务规则替换数据字段内容,比如必要的数据脱敏过程,同时可实现无效数据、缺失数据的替换处理
- 时间规范化:对各类运维数据中的时间字段进行格式统一转换
- 预聚合计算:对数值型字段或指标类数据基于滑动时间窗口进行聚合统计计算,如取1分钟CPU平均值
4.3. 数据存储
- 数据需要进行实时全文检索,分词搜索。可选用主流的 ElasticSearch 引擎
- 时间序列数据(性能指标),主要以时间维度进行查询分析的数据,可选用主流的rrdtool、graphite、influxdb等时序数据库
- 关系类数据,以及会聚集在基于关系进行递归查询的数据可选择图数据库
- 数据的长期存储和离线挖掘以及数据仓库构建,可选用主流的 Hadoop、Spark 等大数据平台
4.4. 离线和在线计算
离线计算:针对存储的历史数据进行挖掘和批量计算的分析场景,用于大数据量的离线模型训练和计算,如挖掘告警关联关系,趋势预测/容量预测模型计算,错误词频分析等场景。
在线计算:对流处理中的实时数据进行在线计算,包括但不限于数据的查询、预处理和统计分析,数据的实时异常检测,以及部分支持实时更新模型的机器学习算法运用等。主流的流处理框架包括:Spark Streaming、Kafka Streaming、Flink、Storm等。
4.5. 算法技术
运维场景通常无法直接基于通用的机器学习算法以黑盒的方式解决,因此需要一些面向AIOps 的算法技术,作为解决具体运维场景的基础。
- 指标趋势预测:通过分析指标历史数据,判断未来一段时间指标趋势及预测值,常见有Holt-Winters、时序数据分解、ARIMA等算法。该算法技术可用于异常检测、容量预测、容量规划等场景。
- 指标聚类: 根据曲线的相似度把多个 KPI 聚成多个类别。该算法技术可以应用于大规模的指标异常检测:在同一指标类别里采用同样的异常检测算法及参数,大幅降低训练和检测开销。常见的算法有DBSCAN、K-medoids、CLARANS等,应用的挑战是数据量大,曲线模式复杂。
- 多指标联动关联挖掘: 多指标联动分析判断多个指标是否经常一起波动或增长。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有Pearson correlation、Spearman correlation、Kendall correlation等,应用的挑战为KPI种类繁多,关联关系复杂。
- 指标与事件关联挖掘: 自动挖掘文本数据中的事件与指标之间的关联关系( 比如在程序 A 每次启动的时候 CPU 利用率就上一个台阶)。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有 Pearson correlation、J-measure、Two-sample test等,应用的挑战为事件和KPI种类繁多,KPI测量时间粒度过粗会导致判断相关、先后、单调关系困难。
- 事件与事件关联挖掘: 分析异常事件之间的关联关系,把历史上经常一起发生的事件关联在一起。该算法技术可用于构建故障传播关系,从而应用于故障诊断。常见的算法有 FP-Growth、Apriori、随机森林等,但前提是异常检测需要准确可靠。
- 故障传播关系挖掘:融合文本数据与指标数据,基于上述多指标联动关联挖掘、指标与事件关联挖掘、事件与事件关联挖掘等技术、由 tracing 推导出的模块调用关系图、辅以服务器与网络拓扑,构建组件之间的故障传播关系。该算法技术可以应用于故障诊断,其有效性主要取决于其基于的其它技术。
5. 顶会推荐
ACM SIGCOMM
ACM IMC
ACM/USENIX NSDI
ACM MobiSys
ACM CoNEXT
ACM MobiCom
ACM SIGMETRICS
IEEE INFOCOM
ACM KDD
USENIX Security
IEEE Security & Privacy
ACM CCS
NDSS
6. 后记
总而言之,AIOps就是利用机器学习来做一些运维工作。涉及到行业知识、运维知识、机器学习知识,是一个很大的研究方向,可以细分为很多小的研究方向。
AIOps围绕质量保障、成本管理和效率提升的基本运维场景,逐步构建智能化运维场景。在质量保障方面,保障现网稳定运行细分为异常检测、故障诊断、故障预测、故障自愈等基本场景;在成本管理方面,细分为指标监控,异常检测,资源优化,容量规划,性能优化等基本场景;在效率方面,分为智能预测,智能变更、智能问答,智能决策等基本场景(注:三者之间不是完全独立的,是相互影响的,场景的划分侧重于主影响维度)。
每一个小方向,都是一个研究点,最终成果是一个学件。通过学件的组合,就构成了AIOps平台。
更多内容请参考书签中给出的链接。