1. 前言
很久,都不再关心百度谷歌对自己博客的收录,只是把博客当做生活的记录。今天,突然想稍微搞下SEO,然后就有了这篇博文。
2. 过程
1、生成站点地图
1 | npm install hexo-generator-sitemap --save |
提示警告,不过可以忽略。
1 | npm WARN optional Skipping failed optional dependency /chokidar/fsevents: |
在博客目录的_config.yml中添加如下代码(貌似不加也可以,反正我没加)
1 | sitemap: |
2、验证网站
Google验证网站的方式是文件验证;百度验证网站的方式有三种,文件验证、html标签验证、CNAME验证。
郝同学采用文件验证方式,下载验证文件,放到hexo/source目录下,hexo g,hexo d,即可发布验证文件到服务器上。
3、添加站点地图
分别登录Google Search Console,和百度站长平台,添加站点地图。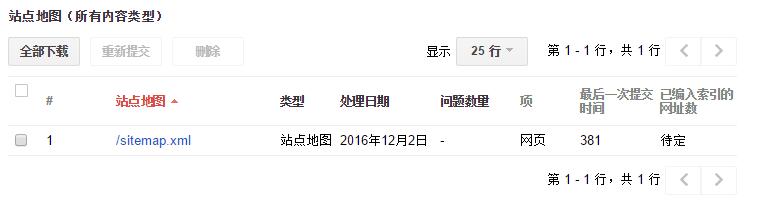
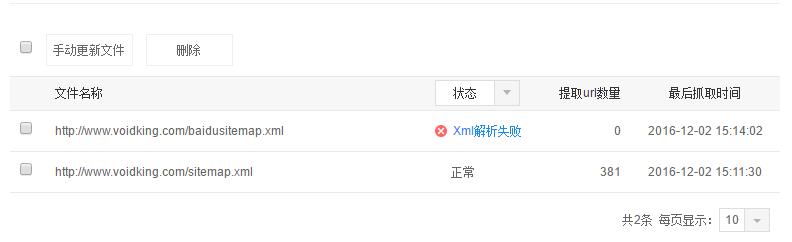
3. 问题
由上面两个图可以看出,sitemap.xml没有问题,但是baidusitemap.xml解析会出错。访问http://www.voidking.com/baidusitemap.xml,看到详细报错。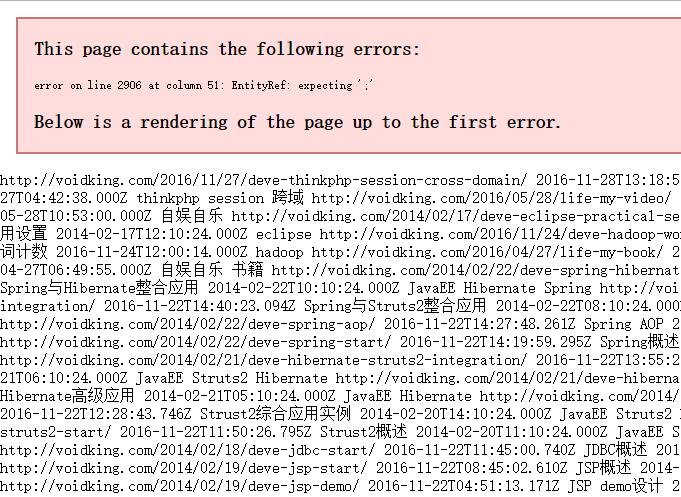
xml解析器在遇到字符“&”时,会把“&”当做一个实体引用的开始,而去寻找这个实体引用的结束符号“;”,
在xml文档中,像“&”这样的预定义的实体引用一共有5个,分别是“&”、“<”、“>”、“’”、“””。
解决方法一:
把实体引用编码后使用,即
1 | 把“&” 编码为 “&” |
1 | <loc>url&mb=bt</loc> |
替换为:
1 | <loc>url&mb=bt</loc> |
解决方法二:
在标记CDATA中,所有的标记、实体引用都被忽略,而被“xml解析器”一视同仁地当做原始字符数据看待,CDATA的形式如下:
针对本文上面的问题,即把原来代码中的:
1 | <loc>url&mb=bt</loc> |
替换为:
1 | <loc><![CDATA[url&mb=bt]]></loc> |
使用CDATA需要注意的两点,1、由于CDATA的结束符号是“]]>”,所以CDATA中不能包含“]]>”。2、由于CDATA中的所有标记、实体引用都被忽略,所以CDATA不能嵌套使用。
4. 后记
然而,上面的问题并没有找到解决办法,那就留个坑吧。如果看到这篇文章的同学找到解决办法,希望能给我留言,在此谢过。
5. 书签
站点信息_站长工具_站点重要数据概览_百度站长平台
http://zhanzhang.baidu.com/dashboard/index
Search Console - 首页
https://www.google.com/webmasters/tools/home?hl=zh-CN
Hexo生成sitemap站点地图的方法
http://blog.kenai.cc/article/hexo/hexo-skills/
hexo干货系列:(六)hexo提交搜索引擎(百度+谷歌)
http://www.jianshu.com/p/619dab2d3c08
关于xml特殊符号报错EntityRef: expecting ‘;’
http://bbs.phome.net/showthread-13-330736-0.html