1. 前言
Hadoop是一种分布式系统框架,组件包括HDFS、MapRedure和Yarn。
本文中,我们学习在 Linux 系统中安装 Hadoop。
参考文档:
Hadoop下载地址:
2. 安装Hadoop1.2.1
3. 安装JDK1.8
安装jdk-8u161,参考文档《全平台安装JDK》
3.1. 下载Hadoop安装包
1 | wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz |
3.2. 修改Hadoop配置
1、修改hadoop-env.sh
1 | cd /opt/hadoop-1.2.1/conf/ |
修改JAVA_HOME。
1 | export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_161 |
2、修改core-site.xml,内容如下:
1 |
|
3、修改hdfs-site.xml,内容如下:
1 |
|
4、修改mapred-site.xml,内容如下:
1 |
|
5、修改/etc/profile,修改PATH如下:
1 | export HADOOP_HOME=/opt/hadoop-1.2.1 |
生效,source /etc/profile。
6、测试
1 | hadoop |
如果出现COMMAND提示,则表明安装配置成功。
如果出现:Warning: $HADOOP_HOME is deprecated.
这是因为新版的hadoop废弃掉了HADOOP_HOME这个变量。若要除去这个警告,要么换用HADOOP_PREFIX,要么在hadoop-env.sh添加一行:
1 | export HADOOP_HOME_WARN_SUPPRESS=1 |
详情参考文档:Warning: $HADOOP_HOME is deprecated.的原因以及解决方法
3.3. 启动Hadoop
1、namenode格式化
1 | hadoop namenode -format |
2、启动hadoop
1 | cd /opt/hadoop-1.2.1/bin |
3、检查是否启动成功
1 | jps |
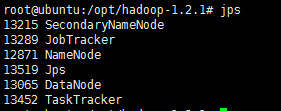
如果看到上图中的进程,则表明启动成功。
4、查看hadoop/hdfs中有哪些文件
1 | hadoop fs -ls / |
至此,hadoop安装完成。
4. 安装Hadoop2.10.2
5. 安装JDK1.8
安装jdk-8u161,参考文档《全平台安装JDK》
5.1. 下载Hadoop安装包
1 | wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz --no-check-certificate |
5.2. Hadoop配置使用JDK
1、修改hadoop-env.sh
1 | cd /usr/local/hadoop/hadoop-2.10.2 |
修改JAVA_HOME为绝对路径。
1 | export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_161 |
2、验证环境
1 | ./bin/hadoop version |
5.3. 单机测试运行
1 | mkdir ./input |
看到结果1 dfsadmin表明运行成功。
5.4. 配置HDFS
伪分布式部署:
- 在一台机器上安装,使用的是分布式思想,即分布式文件系统,非本地文件系统。
- Hdfs涉及到的相关守护进程(namenode,datanode,secondarynamenode)都运行在一台机器上,都是独立的
java进程。 - 用途比 Standalone mode 多了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交
互。
1、修改etc/hadoop/core-site.xml
1 | <configuration> |
配置参考文档:hadoop2.10.2 core-default.xml
2、修改etc/hadoop/hdfs-site.xml
1 | <configuration> |
配置参考文档:hadoop2.10.2 hdfs-default.xml
3、格式化namenode
1 | ./bin/hdfs namenode -format |
执行完成,没有报错,当前目录中出现了tmp目录,表明格式化成功。
4、启动hadoop服务
1 | ./sbin/start-dfs.sh |
需要三次输入当前用户的密码。
5、查看hadoop进程
1 | jps -l |
6、浏览器访问
浏览器访问 http://192.168.56.101:50070
可以看到 NameNode 和 Datanode 的信息。
5.5. 配置免密启动
启动hadoop时需要输入密码,这个比较麻烦,可以通过配置免密登录省去输入密码的步骤。
1 | ssh-keygen |
5.6. 停止hadoop服务
1 | ./sbin/stop-all.sh |