spark-on-k8s-operator: Kubernetes operator for managing the lifecycle of Apache Spark applications on Kubernetes. The Kubernetes Operator for Apache Spark aims to make specifying and running Spark applications as easy and idiomatic as running other workloads on Kubernetes. It uses Kubernetes custom resources for specifying, running, and surfacing status of Spark applications.
spark-on-k8s-operator工作流程: 1、提交sparkApplication的请求到api-server 2、把sparkApplication的CRD持久化到etcd 3、operator订阅发现有sparkApplication,获取后通过submission 4、runner提交spark-submit过程,请求给到api-server后生成对应的driver/executor pod 5、spark pod monitor会监控到application执行的状态(所以通过sparkctl可以通过list、status看到) mutating adminission webhook建svc,可以查看spark web ui
""" A simple example demonstrating Spark SQL Hive integration. Run with: ./bin/spark-submit examples/src/main/python/sql/hive.py """ # $example on:spark_hive$ from os.path import abspath
from pyspark.sql import SparkSession from pyspark.sql import Row # $example off:spark_hive$
if __name__ == "__main__": # $example on:spark_hive$ # warehouse_location points to the default location for managed databases and tables warehouse_location = abspath('spark-warehouse')
# spark is an existing SparkSession spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive") spark.sql("LOAD DATA LOCAL INPATH '/opt/spark/examples/src/main/resources/kv1.txt' INTO TABLE src")
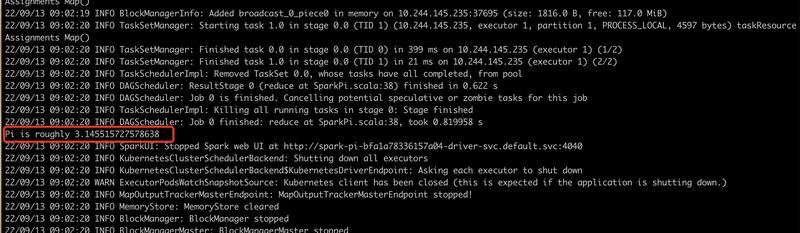
# Queries are expressed in HiveQL spark.sql("SELECT * FROM src").show() # +---+-------+ # |key| value| # +---+-------+ # |238|val_238| # | 86| val_86| # |311|val_311| # ...
# Aggregation queries are also supported. spark.sql("SELECT COUNT(*) FROM src").show() # +--------+ # |count(1)| # +--------+ # | 500 | # +--------+
# The results of SQL queries are themselves DataFrames and support all normal functions. sqlDF = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
# The items in DataFrames are of type Row, which allows you to access each column by ordinal. stringsDS = sqlDF.rdd.map(lambda row: "Key: %d, Value: %s" % (row.key, row.value)) for record in stringsDS.collect(): print(record) # Key: 0, Value: val_0 # Key: 0, Value: val_0 # Key: 0, Value: val_0 # ...
# You can also use DataFrames to create temporary views within a SparkSession. Record = Row("key", "value") recordsDF = spark.createDataFrame([Record(i, "val_" + str(i)) for i inrange(1, 101)]) recordsDF.createOrReplaceTempView("records")
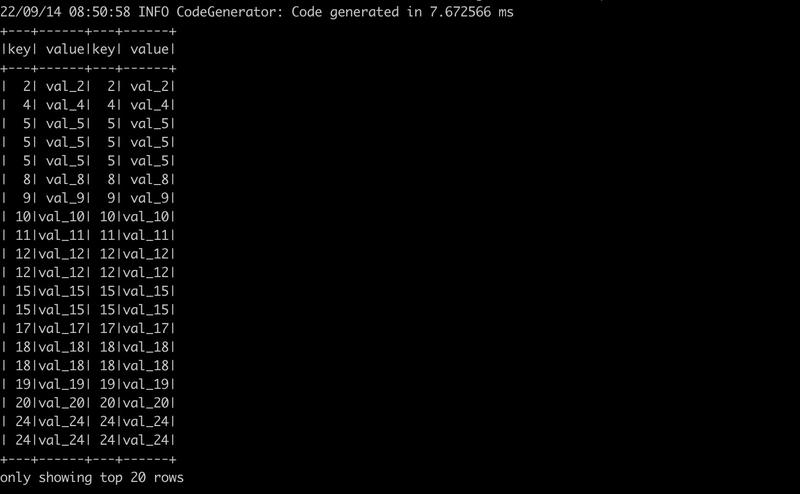
# Queries can then join DataFrame data with data stored in Hive. spark.sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show() # +---+------+---+------+ # |key| value|key| value| # +---+------+---+------+ # | 2| val_2| 2| val_2| # | 4| val_4| 4| val_4| # | 5| val_5| 5| val_5| # ... # $example off:spark_hive$