1. 前言
机器学习标志着计算机科学、数据分析、软件工程和人工智能领域内的重大技术突破。AlphaGo 战胜人类围棋冠军、人脸识别、语音识别、图片识别、大数据挖掘、自动驾驶等等,都和机器学习密切相关。
机器学习其实很简单,而且很有趣。
机器学习是什么?我们生活在一个有人类和计算机的世界,人类和计算机的一大不同点是,人类能从过去的经验中学习,而计算机只能执行指令,它们需要被编程。现在的问题是,我们能让计算机从过去的经验中学习吗?答案是我们能这么做。这就是机器学习的目的,教会计算机利用过往的经验完成指定任务。当然,对计算机来说,过去的经验就是被记录的数据。
2. 先修条件和要求
1、掌握中级编程知识,可以通过“编程入门”纳米学位、其他编程入门课程项目或其他软件开发实战经验获得,相关知识包括:
- 字符串、数值和变量
- 语句、操作符和表达式
- 列表、元组和字典
- 条件、循环
- 过程、对象、模块和库
- 故障诊断和调试
- 调研和文档
- 解决问题
- 算法和数据结构
2、掌握中级统计学知识,可以通过优达学城的统计学入门课程获得,相关知识包括:
- 总体,样本
- 均数、中间值、众数
- 标准误差
- 方差,标准差
- 正态分布
- 精度和准确度
3、掌握中级微积分和线性代数知识,这些知识可以通过线性代数复习课获得,相关知识包括:
- 导数
- 积分
- 级数展开
- 通过特征向量和特征值进行矩阵运算
我们为你准备了一些学习扩展资料,点击这里查看。
3. 决策树
假设我们是苹果或谷歌应用商店,我们的目标是为用户推荐应用。对每个用户,我们向其推荐最有可能下载的应用。我们有一张用来制定推荐规则的数据表。
我们有6个用户信息,包括性别、年龄和下载过的应用。从表中可以看出,年龄比性别更适合用来预测用户会下载什么应用。经过分析,我们可以得到一个决策树。
现在我们一旦我们有了新用户,就可以将决策树应用于他们的数据,并向他们推荐决策树得出的应用。
显然,我们并不总能得到与数据良好匹配的决策树,我们将学习一个算法,用来帮助我们找到和数据最匹配的决策树。
4. 朴素贝叶斯
我们再来看下一个例子,我们将搭建一个垃圾邮件检测分类器。
我们有100封邮件,其中已经手工标记出了25封垃圾邮件,剩下的75封被称为非垃圾邮件。现在我们来思考一封垃圾有家可能会显示出什么特征,并对这些特征进行分析。例如,可能有一个特征包含单词“cheap”,认为一封包含了单词cheap的邮件可能是垃圾邮件,是合理的。我们来分析这一判定,我们发现25封垃圾邮件中有20封包含单词“cheap”,其余75封正常邮件的5封包含单词“cheap”。我们暂时不理会剩下的不含“cheap”的邮件,只关注那些包含cheap的邮件。
请问,如果有一封邮件包含单词“cheap”,那么它是垃圾邮件的概率是多少?答:80%。
即,如果一封邮件包含单词“cheap”,那么它的垃圾邮件的概率为80%,于是我们把这个特征的关联概率设为80%,并用它来标记新邮件是否为垃圾邮件。
我们也可以检查其他特征,尝试找出它们的关联概率。比如我们查看邮件是否包含拼写错误,发现包含拼写错误的邮件为垃圾邮件的概率为70%。接着查看缺少标题的邮件,发现它们是垃圾邮件的概率为90%。
当我们收到新邮件,我们可以结合这些特征来猜测新邮件是否是垃圾邮件,这个算法叫做朴素贝叶斯算法。
5. 梯度下降
假如我们现在正身处山顶(珠穆朗玛峰),我们的目标是抵达山底,应该采取什么策略?
我们可以一步一步来。我们查看四周可以走的许多选项,在其中找到下降距离最大的方向,下降一步。然后重复这个步骤,查看四周,找到下降距离最大的方向,下降一步。重复此步骤,直到完成下山。这个算法,叫做梯度下降。
你可以把这座山想象成要解决的问题,把山底当做对问题的解答。我们解决这个问题的过程,就是总是顺着指向答案的方向小步前进。
6. 线性回归
假设我们正在研究房地产市场,我们的任务是预测给定面积的房屋的价格。这里有一栋较小的房子售价为$70000,一栋较大的房子售价为$160000,我们希望估计一栋中等面积的房子的价格,应该如何来做?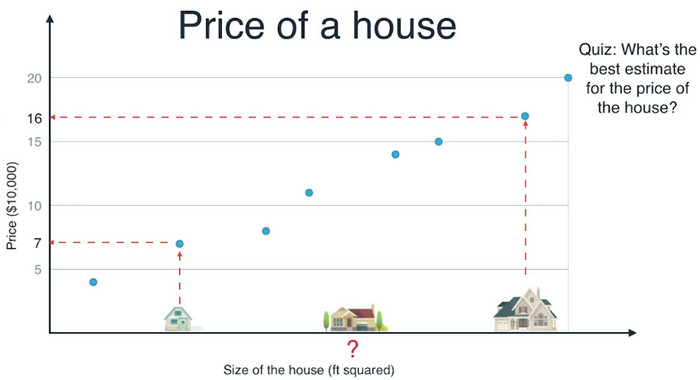
图中的蓝色数据点,是我们收集的过去的房屋数据。
我们可以看到这些数据点似乎排成一条直线,我们可以画出一条对拟合数据的直线。
根据这条直线,我们可以预测中等房子的价格为$120000。这个方法叫做线性回归。
你可以把线性回归想象成一个画家,他检查数据并画出穿过数据区域的最佳拟合直线。你或许会问,我们如何找到这条线?
我们来看一个例子,我们尝试找出这三个点的最佳拟合直线。
我们假设自己是计算机,因此不能直接用视觉来判断。我们随机地画一条直线,检查这条直线的效果如何,为此我们需要计算误差。我们将检查这三个点与拟合直线的距离,我们把这三个距离之和,称为误差。现在四处移动这条线,看是否能减小误差。移动后,再次计算误差。如果误差变大,则说明方向错误。如果误差变小,则说明方向正确。我们发现误差变小了,因此决定采用这次移动。如果重复几次这个步骤,我们总能继续减小误差,最终得到一条拟合曲线作为很好的解决方案。这种最小化误差的通用方法叫做梯度下降(gradient descent)。
在实际使用中,我们并不希望使用数值为负的距离,我们会使用数据点到拟合直线的距离的平方,而不是距离本身。这种方法叫做最小二乘法(least squares)。
我们再次回到珠穆朗玛峰顶,尝试找出到达山底的下降路径。在这个背景里,我们所处的位置越高,代表当前的误差越大,下降高度就意味着减小误差。我们该怎么做?我们查看四周,寻找能下降更多高度的路径,这等价于四处移动拟合直线来最大程度减小误差。举例来说,这个方向似乎就是高度下降最大的方向,我们朝着这个方向前进一步,这等价于沿着能够最大程度减小误差的方向移动拟合曲线,即移动直线让它更加接近这三个点。现在我们减小了误差,也就是更加靠近了山底。然后我们重复以上的过程,查看四周并判断能够最大程度下降的方向。或者等价地,能够使拟合直线更加靠近数据点的方向。然后我们不断地重复此过程,寻找高度下降最大的方向,或者使拟合直线更加靠近数据点的方向,不断减小误差直到其达到最小值,也就得到了最佳拟合直线。
7. 逻辑回归
假设我们是一所大学的招生办公室,正在决定录取哪些学生。根据如下两条信息,我们将录取或拒绝他们。录取考试成绩,和他们的课程成绩。例如,学生1考试成绩为9,课程成绩为8,这名学生最终被录取了。还有一名学生2,考试成绩为3,课程成绩为4,最终没有被录取。现在有一位新提交申请的学生3,考试成绩为7,课程成绩为6,我们是否应该录取他?为此,我们首先把他们的数据画在坐标系中,x轴代表考试成绩,y轴代表课程成绩。
为决定是否录取学生3,我们尝试在录取数据中寻找规律。为此我们检查曾经申请过的学生,被录取或拒绝的数据。录取的点代表过去被录取的学生,红色的点代表曾经被拒绝的学生。
我们来仔细查看数据,红色的点和绿色的点似乎可以被一条线很好地分开。在这条线上方的大部分点是绿色的,而下方的大部分点是红色的,但有些数据点例外。我们以这条线为模型,每当接到新的学生申请,我们把他们的成绩画在坐标图上。如果数据点是在这条线的上方,那么预测他们会被录取;如果数据点在下方,则预测他们会被拒绝。学生3的数据坐标为(7,6),位于直线上方,因此我们判断这个学生会被录取。这种方法叫做逻辑回归(Logistic Regression)。
现在的问题是,我们如何找到这条能最好地分割数据点的线?来看一个简单的例子,如何画出一条线以最好地区分绿色数据点和红色数据点?
计算机无法依靠视觉来画出这条线,所以我们从画一条像这样随机的线开始。有了这条线,我们再随机地规定,位于线上方的点为绿色,下方的点为红色。然后就像线性那样,我们先计算这条线的效果。一个简单的测量误差的标准是出错的数目,即被错误归类的数据点的数量。这条线错判了两个点,一个红色的点和一个绿色的点。仍然和线性回归类似,我们移动这条线,通过梯度下降算法,最小化错误数量。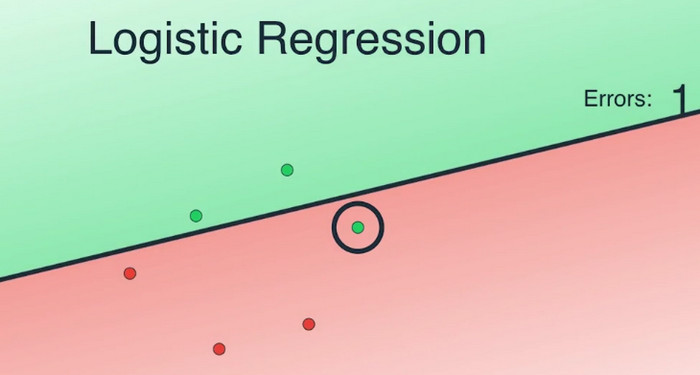

实际使用中,为了正确地使用梯度下降算法,我们需要最小化的并不是错误数目。取而代之的是,能代表错误数目的对数损失函数(log loss function)。
最初6个数据,有4个被正确分类,它们是两个红色和两个绿色;2个被错误分类,它们是一个红色和一个绿色。误差函数会对这两个被错误归类的数据点施加很大的惩罚,而对四个被正确分类的数据点施加很小的惩罚。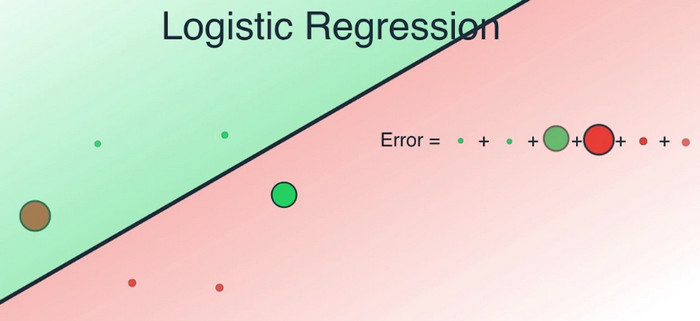
现在四处移动这条线以将误差降到最小。移动直线后,可以看到有些误差减小了,有些增加了,但总体上,误差之和变小了,因为我们正确归类了之前被错判的两个点。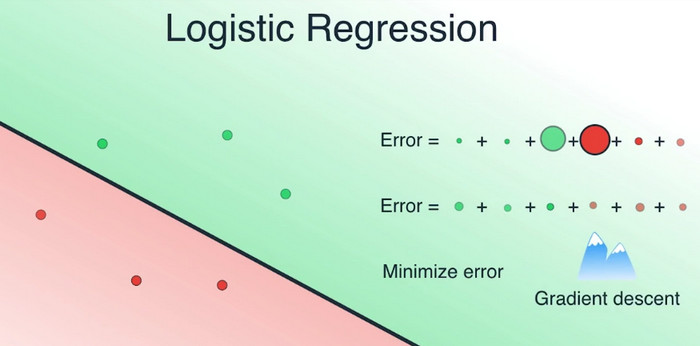
这个过程的意图是,找到能最小化误差函数的最佳拟合曲线。
我们如何最小化误差函数?依旧是使用梯度下降算法。
我们再次回到珠穆朗玛峰,我们所在的位置很高,因此此时有很大的误差,我们探索四周寻找下降最大的方向。或者等价的,寻找能通过移动直线最大程度减小误差的方向。我们决定沿着这个方向前进一步,减小了函数误差。重复这个步骤,沿着最大程度减小误差的方向前进一步。到达了山底,则说明我们已经将误差减少到了最小值。
8. 支持向量机SVM
我们更进一步学习把数据一分为二的艺术。我们看这6个点,似乎有很多条线可以分开它们。例如,这条蓝色的和黄色的。请问,那条线可以把数据更好地分开?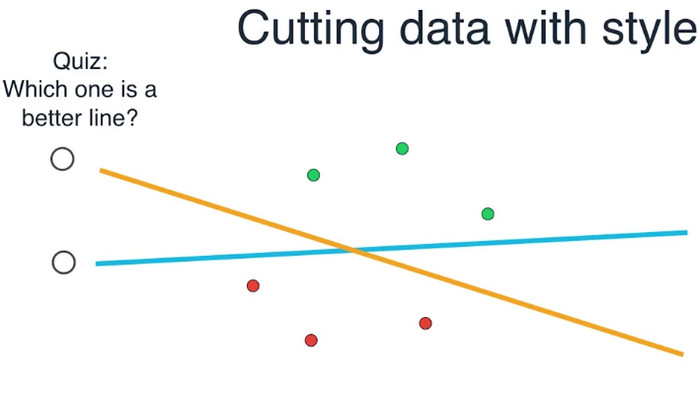
看这条蓝色的线,似乎它是失败的,它太靠近这两个点了。如果我们想要最小化误差,它会误分到一个或多个点。这条黄线似乎是一个更好的划分,考虑到它能够来自于所有的点进行划分。所以,似乎最好的线是这条黄色的。
现在的问题是,我们如何能够找到这条黄色的线?
在找这条黄色的线之前,让我们事实上来找一个度量方式,它可以告诉我们黄色的线更好。那么,第一件事情就是观察这些远离边界的点,它们对于我们的决定并不重要,所以让我们忘掉这些点,只考虑那些离边界近的点。事实上,我们真正要关注的是点到两条直线的距离。什么让我们知道了黄的线更好呢?这条黄色的线更好,是因为它距离这些点更远。那么,我们观察这四个点的距离,最小的距离就是我们度量点离直线到底有多近。这意味着我们必须要考虑的,就是这四个距离的最小值,那是我们度量线离点到底有多近的方式。我们称这个度量为距离。
所以我们得出结论,黄色的线更好。因为在黄线中,这些距离中最小的距离,比蓝线中最小的距离大。这就是我们需要处理的函数,这四个距离中的最小值。我们的目标是使这个最小值尽可能的大,换句话说,我们需要最大化这个距离。我们能够怎么最大化这个距离呢?没错,梯度下降。这里也有其他方法能够使用,之后的课上会学到。这个方法叫做支持向量机,支持,是因为靠近边界的点被称为支撑。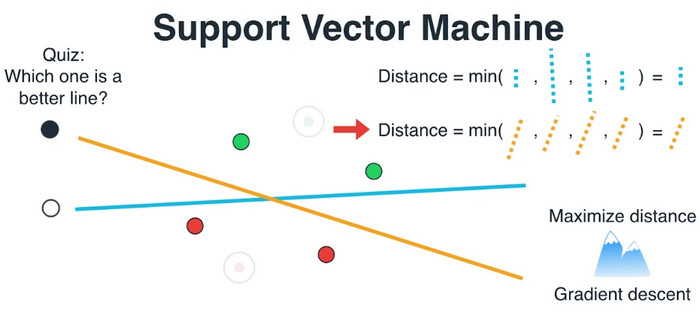
9. 神经网络

我们更加仔细地观察这个模型,这个模型接受或者拒绝学生。比如有一个学生4,他在这次考试成绩中得到了9分,但他的课程成绩是1。根据我们的模型,这个学生应该被接受。因为他在这条线的上面,但是这似乎不对,因为这个学生有一个非常低的课程成绩,不应该被接受。
所以想要用一条直线来区分这里的数据,已经不合适了。也许真实的数据,应该像那些低的考试成绩或者低的课程成绩的都不应该被接受,所以这条线已经不能分离这些点了。那么,我们该怎么做呢?也许是一个圆,也许是两条线。
让我们试一下两条线,我们能够怎么找到这两条线呢?我们可以通过梯度下降来最小化一个和之前相似的对数损失函数。这被称为神经网络(neural network)。
现在问题是,为什么这被称为神经网络?
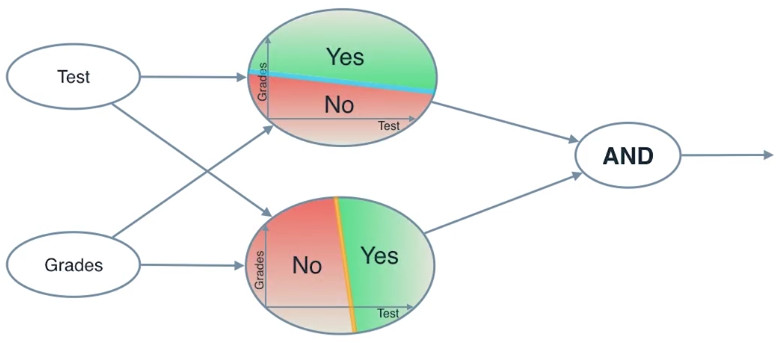
比如我们在一台非常慢的电脑上工作,一个时间只能处理一件事,请问这个区域的点被两条线区分开了吗?我们必须把它分成两个单独的问题。第一个问题是,这个点在蓝线之上吗?第二个问题是,这个点在黄线之上吗?第三个问题是,第一个问题和第二个问题的答案都是“yes”吗?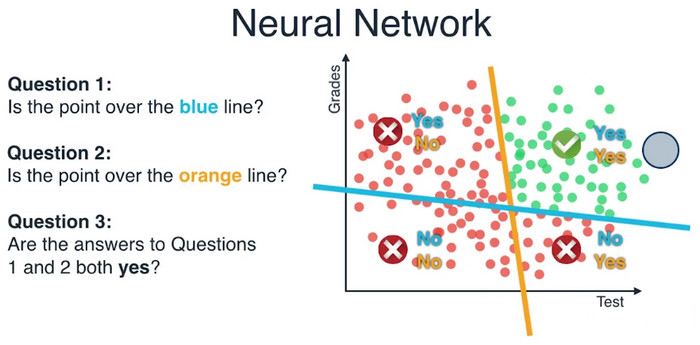
假设我们把(1,8)作为输入,可以得到如下结果:
我们把这三个问题合成到一起,就得到了一个神经网络。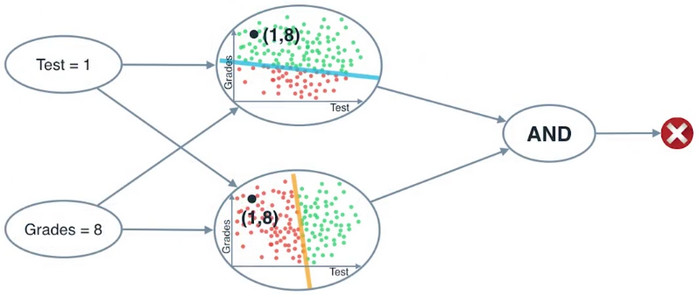
把“and”节点看成和前两个节点相同,可以得到最终神经网络的样子。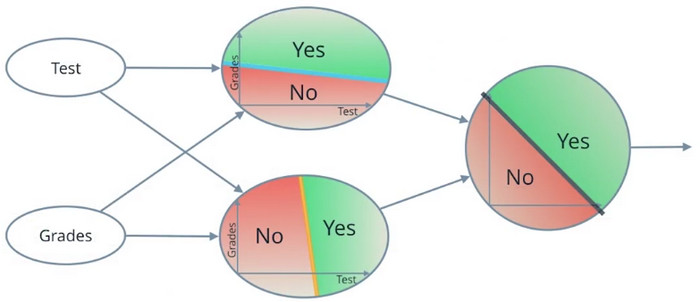

左边,我们叫做输入层;中间,我们叫做隐藏层,会帮助我们计算;右边,我们叫做输出层。
这是一个简单的神经网络,但是能够看出如何在中间增加更多的节点或增加更多的层,帮助我们映射更加复杂的问题,甚至在三维空间或者更高维的空间。神经网络是非常强的机器学习算法,其被使用在大多数人工智能项目中,比如面部识别、语音识别、下棋和驾驶。我们称它为神经网络是因为这些节点像大脑里的神经元,神经元会把输入和其他神经元的输出以一种神经脉冲的形式,决定是否激活这个神经脉冲。在我们的情况中,神经元把输入和其他神经元的输出以数字的形式,决定返回一个0或1。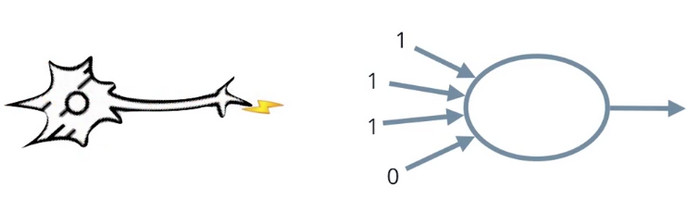
10. 核函数
现在我们学习另外一种非常强大的方法,来分开平面上的点。
假设我们有4个点像这样排列,我们想要分开它们,似乎一条线不能完成这个任务,因为它们已经在一条线上面。我们要跳出思维定式,一个方式是用一个曲线来分开它们,另外的方式事实上是在平面外考虑。想象一下这些点正在一个三维的空间中,有4个点在平面上,对于第三个维度,我们增加一个额外的z轴。如果我们能够找到一个方式来提升这两个绿色的点,那么我们就能够用平面分开它们。
那么哪一个是更好的解决办法?在一个平面里用一条曲线分开这些点,还是在空间里用平面分开它们?实际上,这两个其实是相同的办法。这种方法被称为核方法(kernel method),在支持向量机中它被很好的使用。
我们接下来学习曲线办法的更多细节。首先我们把坐标放在点上,我们需要的是一种办法,能够从红色的点中区分出绿色的点。如果点的坐标是(x,y),也许我们需要一个方程,变量是x和y。对于绿色的点,给我们一个大的值;对于红色的点,给我们一个小的值。或者是相反的情况。那么下面哪个方程能够解决这个问题呢?
这不是一个简单的问题,我们先来做一个表格。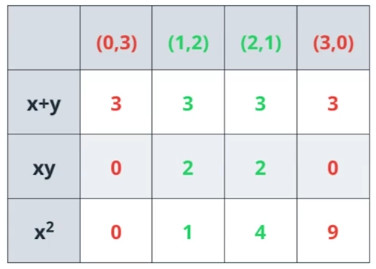
这些等式中,哪一个能够分离绿色的点和红色的点?x+y对于每个点都是结果3,无法分离;x的平方,对于红色点的结果有大有小,绿色点的结果也有大有小,无法分离;xy对于红色点结果为0,绿色的点结果为2,可以分离。因为这是一个函数,红色的点给我们一个值,绿色的点又给我们另外一个值,这个函数能够区分开红色和绿色。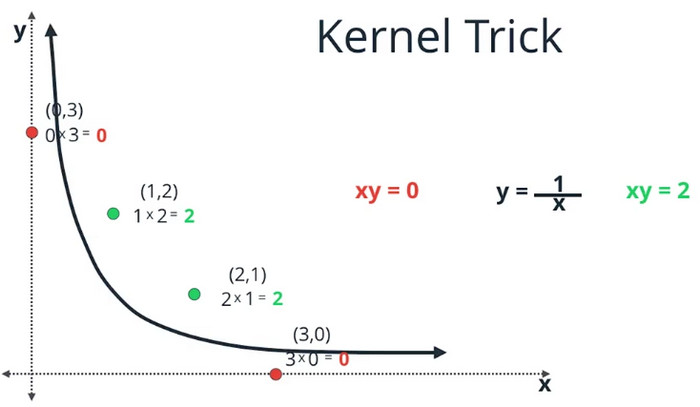
这里我们有4个点,坐标是(x,y),还有一个坐标的乘积xy。对于红色的点,我们有乘积xy=0;对于绿色的点,我们有乘积xy=2。什么能够分开0和2呢?那就是1,所以我们用式子xy=1就能分开它们。那么,xy=1是什么?这个和y=1/x是一样的。y=1/x的图,就是上面的双曲线。
接下来我们看看在三维空间中发生了什么。
我们有4个点,有一个额外的z轴(用于表示高度)。我们把xy加入我们的核心需求中,换句话说,我们考虑一个二维到三维的映射,把平面上坐标是(x,y)的点映射到了空间中,坐标为(x,y,xy)。
所以,以一个不同的方式,它仍然能够分离这些点,因为它把绿色的点升高到了2,把红色的点留在下面。现在什么可以区分这些点呢?一个平面。这就是在三维空间中可视化核方法的一种方式。
11. K均值聚类
假设我们有一些披萨店,我们想把他们中的三个放到这个城市里。研究发现吃披萨的人大都住在这些地方,我们需要知道哪里是放置他们最优的地方。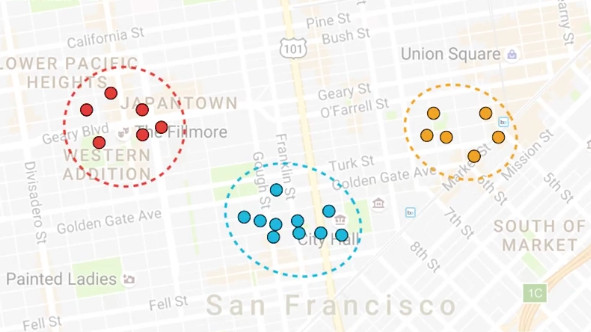
这些房子能够很好地分成三组,红色、蓝色和黄色。在这三个组里每个放一个披萨店似乎行得通,但是电脑并不知道怎么做这个,所以我们需要一个算法来做这件事。
我们随机选择三个地方作为披萨店,它们在星标的地方。每一个房子都会去离他们最近的披萨店,也就是说,黄色房子会去黄色的披萨店,蓝色房子会去蓝色的披萨店,红色房子会去红色的披萨店。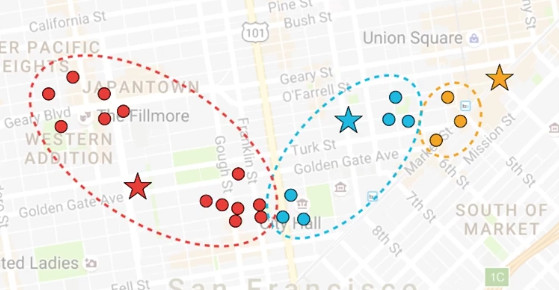
但是现在,黄色房子离黄色披萨店很远。如果移动黄色披萨店到它们的顾客中心,是有意义的,对于蓝色和红色披萨店也一样。那么,让我们移动每一个披萨店到它们的顾客中心。每一次移动披萨店后,离房子最近的披萨店随之发生变化,房子的颜色变成最近的披萨店的颜色。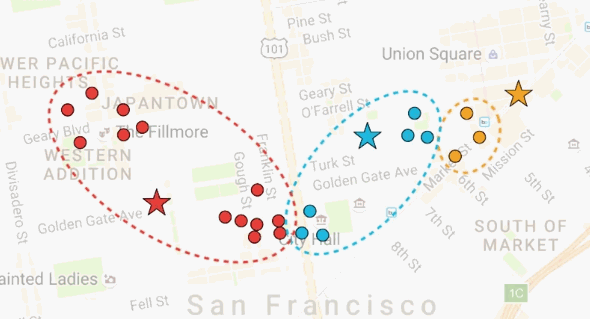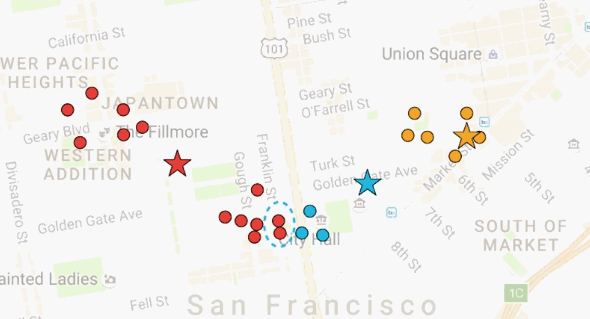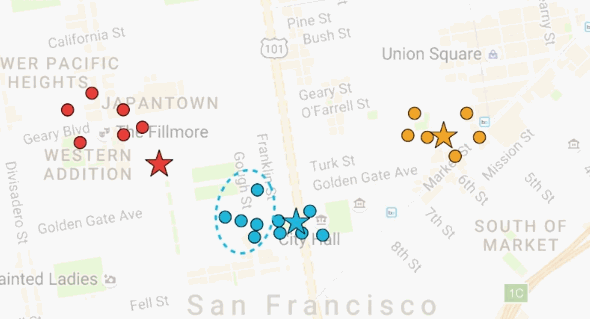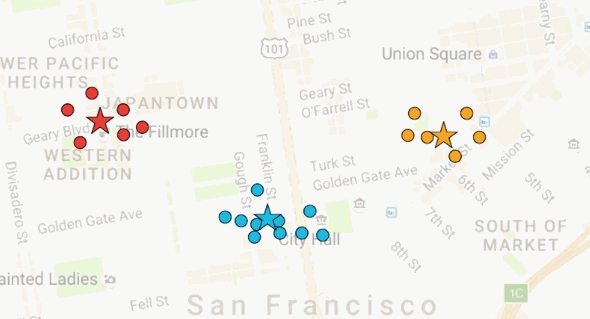
现在,我们有了一个优化的方案。迭代这个过程,我们从随机的解,逼近了理想的解,也就是把披萨店放在顾客住的房子的中心。这个算法叫做K均值聚类(K-Means Clustering)。当我们知道聚类数量的时候,K均值聚类非常实用。现在留下一个问题,如果我们不知道聚类数量,该怎么办?
12. 层次聚类
这里有一个方式,让我们给房子分组,不需要提前知道聚类的详细数量。比如房子被排列成这样:
如果两个房子很近,那么它们应该由共同的披萨店服务。按照这个理念,我们来分组这些房子。把最近两个房子分到一组,重复这个步骤,直到最近的两个房子的距离超过某个界限,这个界限将会控制我们想要这些聚类分开多远。这个算法叫做分层聚类。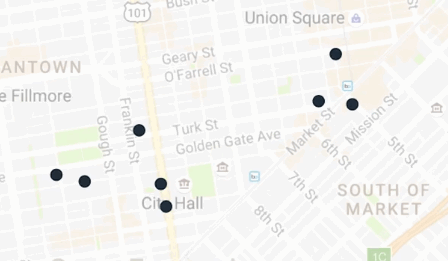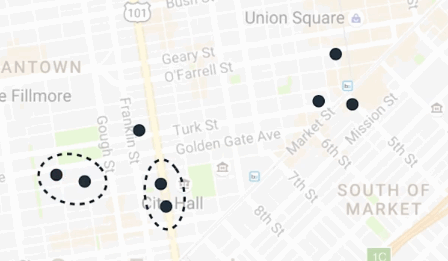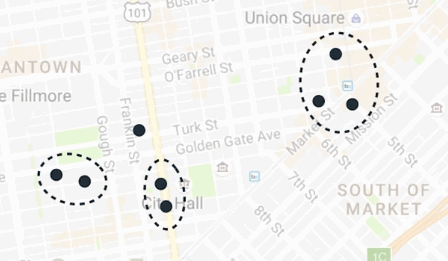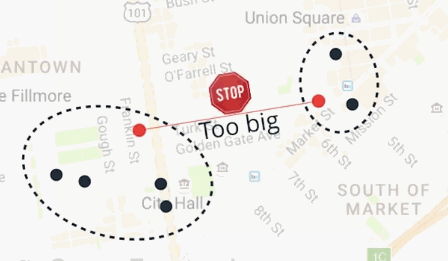
上面的例子可以看出,当我们不知道数目,但是知道想要这些聚类离得多远的时候,分层聚类很实用。
13. 后记
我们学习了很多被用在机器学习中的主要算法,使用线性回归来预测房屋价格,使用朴素贝叶斯来检测垃圾邮件,使用决策树来推荐应用。
我们学会了使用逻辑回归和支持向量机来创建一个模型,使用神经网络和核方法来改善模型。
我们学会了使用聚类算法,在一个城市中如何定位一个披萨店。
还有更多的算法,等待我们以后去学习。
如果给你一个数据集,你怎么知道该挑选哪种算法呢?我们需要学习比较它们,基于运行时间、准确率等等。
我们还能够把算法组合在一起使用。
14. 书签
优达学城-机器学习工程师(中/英)
https://cn.udacity.com/course/machine-learning-engineer-nanodegree--nd009
Udacity GitHub 机器学习项目
https://github.com/udacity/machine-learning/
优达学城论坛
https://discussions.youdaxue.com/c/nd009-machine-learning-engineer-cafe
Latest MLND: Café topics - Udacity Discussion Forum
https://discussions.udacity.com/c/nd009-cafe
Coursera-机器学习
https://www.coursera.org/learn/machine-learning/home/welcome
Coursera-机器学习基础:案例研究
https://www.coursera.org/learn/ml-foundations/home/welcome
Machine Learning Examples - MATLAB & Simulink
https://cn.mathworks.com/solutions/machine-learning/examples.html?s_eid=PSM_da
MATLAB数据分析与挖掘实战——图书配套资料下载
http://www.tipdm.org/ts/578.jhtml
BdRace数睿思_数据挖掘竞赛平台
http://www.tipdm.org/datarace/index.html
微软“机器学习”系列文章(需翻墙)
http://www.msra.cn/zh-cn/research/machine-learning-group/default.aspx
机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1)
https://github.com/ty4z2008/Qix/blob/master/dl.md
从0到1:我是如何在一年内无师自通机器学习的?
http://www.leiphone.com/news/201609/SJGulTsdGcisR8Wz.html
Deep Learning Tutorials
http://deeplearning.net/tutorial/