1. 问题描述
心态爆炸了!火急火燎!一方面马上要交毕业论文,另一方面马上要提交小论文。就当我打算抽出一天先完成小论文时,实验环境崩了!
之前进行迁移实验都好好的,但是今天进行迁移实验的时候,实例经常死机。本着“重启治百病”的思想,重启了两个计算节点,重新挂载了nfs。然后再次迁移时,实例可以从compute2迁移到compute1。但是,实例从compute1迁移到compute2时,compute2就报错!
1 | ERROR oslo_messaging.rpc.server [req-922596a7-f122-45c8-9f91-1446bb855e05 2c04ede78270421da71953f8f07ef115 8de01ef30eed437193725fb759b9992d - default default] Exception during message handling: InvalidCPUInfo: Unacceptable CPU info: CPU doesn't have compatibility. |
重新部署了compute2计算节点,依然是这个错误。重装了compute2计算节点的操作系统,然后重新部署,依然是这个错误!很绝望!
2. 问题分析
重装系统无效,那么大概率是控制节点的锅了!那么问题具体出在哪里?凭什么compute1就好好的,compute2就坏了?是因为控制节点的一些残留信息没有清空吗?数据库中记录说compute2已经没有可用CPU了?数据库中记录说不兼容?还是有缓存或者消息?那么该怎么清空关于compute2的信息?。。。
还有一个关键的问题是,为什么突然就无法兼容了?之前不是好好的么?
然而,没有人可以告诉我答案,搜索引擎不行,社区群聊不行,身边也没有OpenStack的大牛。
现在只想赶紧从OpenStack这个大坑中爬出来,遇到问题根本找不到答案,就问你服不服!
3. 垂死挣扎
3.1. 查看数据库
1、查看数据库密码less /etc/kolla/passwords.yml | grep password
里面有很多密码,我们需要的是nova_database_password。
2、进入mariadb容器docker exec -it mariadb /bin/bash
3、登录mariadb数据库mysql -u nova -p
4、使用nova数据库use nova;
5、查看计算节点的信息select * from compute_nodes\G
3.2. 重命名计算节点
如果,给compute2节点更换hostname和IP呢?比如hostname换成compute3,IP也换成其他的。这样的话,计算节点就不会受控制节点中残留信息的影响了。
1、修改compute2的hostname和IP地址
2、修改multinode文件
控制节点中,把multinode文件中的compute2节点换成compute3,/etc/hosts中添加compute3对应的IP。
3、重新部署kolla-ansible -i ./multinode deploy
4、查看计算服务
1 | . admin-openrc.sh |
3.3. 设置迁移和挂载
参考《OpenStack中虚拟机的在线迁移》,在compute3节点设置OpenStack允许迁移。参考《OpenStack中共享存储的虚拟机在线迁移》,在compute3节点挂载nfs。
1、修改nova.conf的配置vim /etc/kolla/nova-compute/nova.conf,在default中添加:
1 | live_migration_flag=VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE |
2、修改libvirtd.confvim /etc/kolla/nova-libvirt/libvirtd.conf,修改配置如下:
1 | listen_tcp = 1 |
3、挂载nfs
1 | apt-get install nfs-common |
4、重启nova_compute和nova_libvirt
1 | docker stop nova_compute |
3.4. 再次尝试迁移
1、迁移命令nova live-migration demo0 compute3
2、查看状态nova show demo0
3、compute3上查看日志tail -n 20 /var/lib/docker/volumes/kolla_logs/_data/nova/nova-compute.log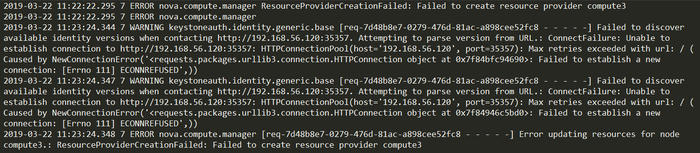
虽然迁移失败,但是好歹是不一样的错误了。。。这个错误以前遇到过,重启计算节点就好了。于是重启compute3节点,但是问题没有解决。
4、测试与控制节点的连接curl http://192.168.56.120:35357,结果为:
1 | curl: (7) Failed to connect to 192.168.56.120 port 35357: Connection refused |
5、在compute1节点上测试与控制节点的连接curl http://192.168.56.120:35357,结果为:
1 | {"versions": {"values": [{"status": "stable", "updated": "2018-02-28T00:00:00Z", "media-types": [{"base": "application/json", "type": "application/vnd.openstack.identity-v3+json"}], "id": "v3.10", "links": [{"href": "http://192.168.56.120:35357/v3/", "rel": "self"}]}, {"status": "deprecated", "updated": "2016-08-04T00:00:00Z", "media-types": [{"base": "application/json", "type": "application/vnd.openstack.identity-v2.0+json"}], "id": "v2.0", "links": [{"href": "http://192.168.56.120:35357/v2.0/", "rel": "self"}, {"href": "https://docs.openstack.org/", "type": "text/html", "rel": "describedby"}]}]}} |
这才是正常的啊!
6、重启compute3并且重新挂载nfs
1 | mount -t nfs 192.168.56.130:/nfs/share/instances /var/lib/docker/volumes/nova_compute/_data/instances/ |
7、再次执行迁移nova live-migration demo0 compute3
依然失败,还是同样的错误。
3.5. IP的坑
百度谷歌想要找到答案?不存在的。折腾了两天,突然灵光一现!
还记得《Kolla安装OpenStack多节点》一文中,控制节点的IP为192.168.56.110。而配置globals.yml时候,kolla_internal_vip_address的值为192.168.56.120。
因此,compute3节点中,nova.conf中的IP有一部分是192.168.56.110,另外一部分是192.168.56.120。
明明所有控制节点的服务都在一个节点上,却有两个IP,看起来就容易闹幺蛾子。实际上,确实闹过幺蛾子!OpenStack刚刚安装成功时,使用192.168.56.120这个IP可以访问到horizon服务,使用192.168.56.110就不可以。后来突然有一天,192.168.56.120这个IP就不能访问horizon了,使用192.168.56.110却可以访问!再后来突然有一天,两个IP都可以访问horizon服务!真的是醉了。。。
这次,会不会也是IP的问题?于是,在compute3上,换一个IP测试访问控制节点。curl http://192.168.56.110:35357,果然可以正常访问!于是,思路就清晰了。
1、修改compute3节点中的nova.conf配置文件vim /etc/kolla/nova-compute/nova.conf,所有的192.168.56.120全部换成192.168.56.110。
2、重启nova_compute
1 | docker stop nova_compute |
3、再次迁移,失败,不过报错变了。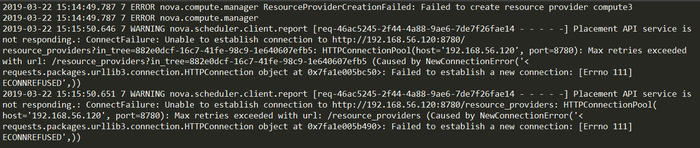
依然是IP问题,看来还有其他配置文件中写了192.168.56.120。
4、修改neutron.conf和chrony.conf文件
1 | vim /etc/kolla/neutron-openvswitch-agent/neutron.conf |
所有120替换为110。
5、重启neutron和chrony
1 | docker stop neutron_openvswitch_agent |
6、再次迁移,依然失败,报错依然失8780端口。
7、重启所有服务,再次迁移,依然失败。
莫非还有什么文件没有注意到?于是放了一个大招,grep -rn "192.168.56.120:8780" *,然而,没有找到包含该配置的文件。
8、重启了compute3,然后,nova_compute无法启动了!启动报错:
1 | /var/lib/docker/volumes/kolla_logs/_data: no such file or directory |
创建了三个文件夹,依然无法启动nova_compute。
4. 破釜沉舟
实在是没办法了,只能使出最后一招:重装整个OpenStack系统!
4.1. 销毁OpenStack环境
1、查看镜像glance image-list
或者进入镜像文件夹查看cd /var/lib/docker/volumes/glance/_data/images
2、导出镜像
1 | glance image-download --file ./ubuntu16-env.img 003ae986-4dd9-45a6-9630-1b80fc8dcab3 |
3、在horizon中删除所有镜像
4、在horizon中关闭并删除所有实例
5、编辑multinode文件,取消所有节点的注释
6、销毁整个OpenStack环境kolla-ansible destroy -i ./multinode --yes-i-really-really-mean-it
4.2. 安装OpenStack
参考《Kolla安装OpenStack多节点》进行OpenStack的安装。
考虑到两个IP的坑,这次安装我仔细阅读了一下globals.yml文件中关于kolla_internal_vip_address的描述:
This should be a VIP, an unused IP on your network that will float between
the hosts running keepalived for high-availability. If you want to run an
All-In-One without haproxy and keepalived, you can set enable_haproxy to no
in “OpenStack options” section, and set this value to the IP of your
‘network_interface’ as set in the Networking section below.
这应该是VIP,网络上未使用的IP将在运行keepalived以获得高可用性的主机之间浮动。如果要在没有haproxy和keepalived的情况下运行多功能一体机,可以在“OpenStack选项”部分中将enable_haproxy设置为no,并将此值设置为“network_interface”的IP,如下面的“网络”部分所述。
看来,kolla_internal_vip_address不应该设置为192.168.56.120,因为我们的环境中不需要haproxy。所以,在配置配置globals.yml的时候,kolla_internal_vip_address应该设置为和控制节点相同的IP:192.168.56.110,同时enable_haproxy设置为no。
安装完成后,导入之前备份的镜像:
1 | . admin-openrc.sh |
4.3. 设置迁移和挂载
参考本文中垂死挣扎部分设置迁移和挂载。
然后,创建实例,分配浮动IP,测试迁移,成功!nice!
5. 罪魁祸首
再次进行迁移,同时启动间隔1ms的ping命令测试停机时间,然后实例迁移后死机了!Ctrl+C关闭ping命令,实例复活。由此猜想是ping命令的锅。
但是,这是一个单向问题!同样是使用间隔1ms的ping命令测试停机时间,实例从compute1迁移到compute2时正常,实例从compute2迁移到compute1时才会死机。就问你神奇不神奇?!
猜测是因为ping的频率太高,给网络或者实例带来了太大的负荷。ping命令降低到10ms一次,双向迁移都正常。
但是,实例从compute1到compute2时,就不会受到ping命令的影响,这次是为什么?两台机器的配置完全相同的啊!诡异,实在是诡异!
更诡异的是,每次迁移的数据居然都通过不同的网卡,也许这次通过eth0(管理网络),下次就通过eth2(外网网络)!还能不能愉快地玩耍了?!
细细回想整个安装流程,突然想到,在安装前设置了三个节点的hosts文件,三个节点通过eth0通信。但是ansible安装OpenStack后,会根据globals.yml中的network_interface(eth1)修改hosts文件,于是hosts中有了两套规则。默认使用hosts文件中靠前的规则,于是我自己设置的规则就把ansible设置的规则覆盖了。eth0既用于节点间通信,又用于实例迁移。由于eth2和eth0属于同一个网段,所以有时会通过eth2网卡进行迁移!
为了验证自己的猜想,修改了三个节点的hosts文件,保留ansible创建的那一份。这样,就指定了迁移时使用的网卡。修改后在控制节点和计算节点重启nova相关服务。
1 | # 计算节点 |
再次迁移实验,迁移数据果然会通过eth1(OpenStack内网网络),而不是eth0或者eth2!而且,双向迁移加1ms的ping命令都可以成功迁移,实例不再死机,问题完美解决!真相大白,罪魁祸首居然是hosts文件!
此外,live_migration_inbound_addr参数也可以指定迁移网络。
6. 风波再起
就当我自以为找到了真相,继续实验时,实例再次出现了实例死机的情况。双向迁移都会偶尔出现死机,而且,使用间隔1ms的ping命令时死机概率会更大。如果使用间隔10ms的ping命令来测试停机时间呢?测出来的停机时间是秒级!Are you kidding me ?
比如同一个迁移,使用两个ping命令进行测试:
1 | sudo ping instance_float_ip -i 0.001 >> ping.log |
理论上,应该测出同样的结果才对,然而他们差了一个数量级!诡异,实在是诡异!哪个才是真正的downtime?无论哪个是真正的downtime,ping命令本身绝对存在重大缺陷!
如果downtime是毫秒级,那么就符合理论上的值,实验可以正常进行。但是,使用间隔1ms的ping命令测试停机时间容易实例死机啊大哥!
如果downtime是秒级,那么问题要么是出在OpenStack配置上面,要么是出在网络上面。
假设问题出在OpenStack的配置上面,于是参考Configure live migrations,先后设置了最大停机时间,设置了自动收敛,设置了后拷贝。但是,问题依旧,那么应该不是OpenStack的配置问题。
假设问题出在网络上面,那么怎么解决呢?给实例的外网(eth3)设置一个单独的网段,不要和管理网络(eth0)在同一个网段?太麻烦。如果,在另外一个实例中对迁移实例进行ping测试呢?这样至少也可以避免了浮动IP的切换问题,是一个好主意。
于是在实例B中运行间隔1ms的ping命令,通过实例间的内网测试实例A,实例A多次迁移,测出的downtime在几十毫秒到几百毫秒不等,而且不会死机。在实例B中使用间隔10ms的ping命令进行测试,测出的downtime在几百毫秒左右,也很合理。所以,不是ping命令的锅?
不管了不管了,总之找到了解决办法!在另外一个实例中对迁移实例使用ping命令通过实例间的内网测试停机时间,而不是在外部机器中使用ping命令通过浮动IP测试停机时间。命令如下:
1 | sudo ping instance_internal_ip -i 0.001 >> ping.log |
7. 后记
因为实例迁移会死机,所以开始了折腾。折腾了一大圈,重启所有节点,重装计算节点,重装系统,重装OpenStack,最后发现实例迁移依然会死机!这就排除了硬件问题,也排除了软件问题。好在最后灵光一现猜测是hosts的问题,不然这个坑是怎么都爬不出不来了。。。只是没想到刚爬出一个坑,又跌进了一个坑,修改了hosts不死机,只是刚好那几次实验都没死机!在使用了间隔1ms的ping命令之后,死机依然频繁。再次折腾OpenStack配置,失败。再次从网络方面考虑,终于找到了解决方案,太不容易了!
今天(3月24日)终于修复了实验环境,但是,已经错过了cloud2019的deadline。有些遗憾,不过和毕业论文相比,只能先牺牲小论文了。近期还有会议,加把劲,做实验,写论文,投稿!