1. 前言
Lisp是Fortran语言之后第二古老的高级编程语言,自成立之初已发生了很大变化。如今,最广为人知的通用的是Lisp方言:Common Lisp和Scheme。
Common Lisp和Scheme有什么不同呢?个人认为,Common Lisp和Scheme,就像狮子和家犬。狮子更加强大,难以驯服;家犬更加小巧,容易驯服。而选择哪一种,取决于实际需要。鉴于郝同学只是需要学习一下函数式编程的思想,所以Scheme足够了。
PS:MIT 的两本著名教材 SICP(Structure and Interpretation of Computer Programs)和 HTDP(How to Design Programs)都是以Scheme为基础的。
2. 安装mit-scheme
1、进入mit-scheme官网,下载对应平台的mit-scheme(下文以windows为例)。
2、安装下载的mit-scheme(下文简称scheme)。
3、双击scheme快捷方式,如果出现如下界面,表明安装成功。
PS:如果打开scheme的时候报错“Requested allocation is too large. Try with smaller argument to –heap”。那么,在程序的快捷方式上右键,属性,在“目标”里加上--heap 512。
4、把安装路径加入环境变量。
例如,我的scheme安装路径为C:\Program Files (x86)\MIT-GNU Scheme,那么,在path中加入C:\Program Files (x86)\MIT-GNU Scheme\bin。同时,新建系统变量MITSCHEME_LIBRARY_PATH,值为C:\Program Files (x86)\MIT-GNU Scheme\lib。
5、测试scheme。
打开命令行,输入mit-scheme,弹出如下界面,表明安装配置成功。
6、退出scheme。
在scheme命令窗口输入(exit),选择y,退出scheme命令窗口。
3. hello world
在scheme命令窗口中输入代码非常麻烦,光标不能回退和上下移动,所以比较简单的方法就是运行已经写完的文件。
3.1. 方法一
1、新建hello.scm文件,内容如下:
1 | ;The first program |
2、运行hello.scm。mit-scheme -load hello.scm,效果如下: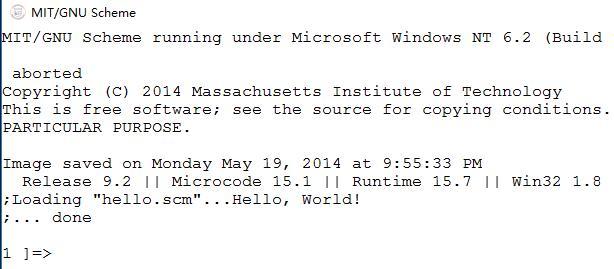
PS:如果此时报错“Requested allocation is too large. Try with smaller argument to –heap”,那么,修改命令为mit-scheme --heap 128 -load hello.scm。
3.2. 方法二
打开mit-scheme窗口后,(cd "e:\\temp"),(load "hello.scm")。
4. 基本语法
4.1. 数据类型
Scheme中的简单数据类型包含 boolean(布尔类型),number(数字类型),character(字符类型) 和 symbol(标识符类型)。
复合数据类型是以组合的方式通过组合其它数据类型数据来获得。包括string、vector、dotted pair、list等。
数据类型详解:
http://www.kancloud.cn/wizardforcel/teach-yourself-scheme/147165
4.2. 代码结构
函数式编程只用“表达式”,不用“语句”。
“表达式”(expression)是一个单纯的运算过程,总是有返回值;“语句”(statement)是执行某种操作,没有返回值。函数式编程要求,只使用表达式,不使用语句。也就是说,每一步都是单纯的运算,而且都有返回值。
原因是函数式编程的开发动机,一开始就是为了处理运算(computation),不考虑系统的读写(I/O)。”语句”属于对系统的读写操作,所以就被排斥在外。
当然,实际应用中,不做I/O是不可能的。因此,编程过程中,函数式编程只要求把I/O限制到最小,不要有不必要的读写行为,保持计算过程的单纯性。
基本格式:(function_name arg0,arg1,...)
示例:
1 | (display "Hello, World!") |
迄今为止我们提供的Scheme示例程序都是s-表达式。这对所有的Scheme程序来说都适用:程序是数据。
Scheme运行一个列表形式的代码结构时,首先要检测列表第一个元素,或列表头。如果这个列表头是一个过程,则代码结构的其余部分则被当成将传递给这个过程的参数集,而这个过程将接收这些参数并运算。
如果这个代码结构的列表头是一个特殊的代码结构,则将会采用一种特殊的方式来运行。常见的特殊的代码结构有begin, define和 set!。
begin可以让它的子结构可以有序的运算,而最后一个子结构的结果将成为整个代码结构的运行结果。define会声明并会初始化一个变量。set! 可以给已经存在的变量重新赋值。
4.3. 过程(函数)定义
4.3.1. 匿名过程
我们已经见过了许多系统过程,比如,cons, string->list等。用户可以使用代码结构lambda来创建自定义的过程。例如,下面定义了一个过程可以在它的参数上加上2:
1 | (lambda (x) (+ x 2)) |
第一个子结构,(x),是参数列表。其余的子结构则构成了这个过程执行体。这个过程可以像系统过程一样,通过传递一个参数完成调用:
1 | ((lambda (x) (+ x 2)) 5) |
4.3.2. 一般定义
如果我们希望能够多次调用这个相同的过程,我们可以每次使用lambda重新创建一个复制品,但我们有更好的方式。我们可以使用一个变量来承载这个过程:
1 | (define add2 |
只要需要,我们就可以反复使用add2为参数加上2:
1 | (add2 4) => 6 |
定义过程还可以有另一种简单的方式,直接用define而不使用lambda来创建:
1 | (define (add2 x) |
4.3.3. 过程的参数
lambda 过程的参数由它的第一个子结构(紧跟着lambda标记的那个结构)来定义。add2是一个单参数或一元过程,所以它的参数列表是只有一个元素的列表(x)。标记x作为一个承载过程参数的变量而存在。在过程体中出现的所有x都是指代这个过程的参数。对这个过程体来说x是一个局部变量。
我们可以为两个参数的过程提供两个元素的列表做参数,通常都是为n个参数的过程提供n个元素的列表。下面是一个可以计算矩形面积的双参数过程。它的两个参数分别是矩形的长和宽。
1 | (define area |
我们看到area将它的参数进行相乘,系统过程*也可以实现相乘。我们可以简单的这样做:
1 | (define area *) |
4.4. apply过程
apply过程允许我们直接传递一个装有参数的list 给一个过程来完成对这个过程的批量操作。
1 | (define x '(1 2 3)) |
通常,apply需要传递一个过程给它,后面紧接着是不定长参数,但最后一个参数值一定要是list。它会根据最后一个参数和中间其它的参数来构建参数列表。然后返回根据这个参数列表来调用过程得到的结果。例如:
1 | (apply + 1 2 3 x) |
4.5. 顺序执行
我们使用begin这个特殊的结构来对一组需要有序执行的子结构来进行打包。许多Scheme的代码结构都隐含了begin。例如,我们定义一个三个参数的过程来输出它们,并用空格间格。一种正确的定义是:
1 | (define display3 |
在Scheme中,lambda的语句体都是隐式的begin代码结构。因此,display3语句体中的begin不是必须的,不写时也不会有什么影响。
display3更简化的写法是:
1 | (define display3 |
4.6. 条件语句
4.6.1. if
最基本的结构就是if:
1 | (if 测试条件 |
如果测试条件运算的结果是真(非#f的任何其它值),then分支将会被运行(即满足条件时的运行分支)。否则,else分支会被运行。else分支是可选的。
1 | (define p 80) |
4.6.2. when 和 unless
当我们只需要一个基本条件语句分支时(”then”分支或”else”分支),使用when 和 unless会更方便。
1 | (define a 10) |
先判断a是否小于b,这个条件成立时会输出倒序的5条信息。
同样的功能还可以像下面这样用unless来写(unless和when的意思正好相反):
1 | (define a 10) |
并不是所有的Scheme环境都提供when和unless。
如果你的Scheme中没有,你可以用宏来自定义出when和unless。
使用if实现相同的程序会是这样:
1 | (define a 10) |
先判断a是否小于b,这个条件成立时会输出正序的5条信息。
在mit-scheme下,中文会显示乱码,为方便查看,建议修改成英文。
4.6.3. cond
多重if结构为:
1 | (define c #\c) |
这样的结构都可以使用cond来这样写:
1 | (cond ((char<? c #\c) -1) |
cond就是这样的一种多分支条件结构。每个从句都包含一个判断条件和一个相关的操作。第一个判断成立的从句将会引发它相关的操作执行。如果任何一个分支的条件判断都不成立则最后一个else分支将会执行(else分支语句是可选的)。
cond的分支操作都是begin结构。
4.6.4. case
当cond结构的每个测试条件是一个测试条件的分支条件时,可以缩减为一个case表达式。
1 | (define c #\c) |
分支头值是#\c 的分支将被执行。
4.6.5. and 和 or
Scheme提供了对boolean值进行逻辑与and和逻辑或or运算的结构。(我们已经见过了布尔类型的求反运算not过程。)
当所有子结构的值都是真时,and的返回值是真,实际上,and的运行结果是最后一个子结构的值。如果任何一个子结构的值都是假,则返回#f。
1 | (and 1 2) => 2 |
而or会返回它第一个为值为真的子结构的结果。如果所有的子结构的值都为假,or则返回#f。
1 | (or 1 2) => 1 |
and和or都是从左向右运算。当某个子结构可以决定最终结果时,and和or会忽略剩余的子结构,即它们是“短路”的。
1 | (and 1 |
4.7. 词法变量
Scheme的变量有一定的词法作用域,即它们在程序代码中只对特定范围的代码结构可见。
1 | (define x 9) |
这里有一个全局变量x,值一直为9;还有一个局部变量x,就是在过程add2中那个字母x。
而set!代码结构可修改变量的赋值。
1 | (set! x 20) |
上面代码将全局变量x的值9修改为20,因为对于set!全局变量是可见的。如果set!是在add2过程体内被调用,那修改的就是局部变量x:
1 | (define add2 |
这里set!在局部变量x上加上2,并且会返回局部变量x的新值。(从结果来看,我们无法区分这个过程和先前的add2过程)。
1 | (define counter 0) |
bump-counter是一个没有参数的过程(没有参数的过程也称作thunk)。 它没有引入局部变量和参数,这样就不会隐藏任何值。在每次调用时,它会修改全局变量counter的值,让它增加1,然后返回它当前的值。下面是一些bump-counter的成功调用示例:
1 | (bump-counter) => 1 |
4.7.1. let 和 let*
并不是一定要显式的创建过程才可以创建局部变量。有个特殊的代码结构let可以创建一列局部变量以便在其结构体中使用:
1 | (let ((x 1) |
和lambda一样,在let结构体中,局部变量x(赋值为1)会暂时隐藏全局变量x(赋值为20)。
局部变量x、y、z分别被赋值为1、2、3,这个初始化的过程并不作为let过程结构体的一部分。因此,在初始化时对x的引用都指向了全局变量x,而不是局部变量x。
1 | (let ((x 1) |
在初始化区域中,可以用先创建的变量来为后创建的变量赋值,let*结构就可以这样做:
1 | (let* ((x 1) |
这个例子完全等价于下面这个let嵌套的程序,更深了说,实际上就是let嵌套的缩写。
1 | (let ((x 1)) |
我们也可以把一个过程做为值赋给变量:
1 | (let ((cons (lambda (x y) (+ x y)))) |
在这个let构结体中,变量cons将它的参数进行相加。而在let结构的外面,cons还是用来创建点对。
4.7.2. fluid-let
一个词法变量如果没有被隐藏,在它的作用域内一直都为可见状态。有时候,我们有必要将一个词法变量临时的设置为一个固定的值,为此我们可使用fluid-let结构。
1 | (fluid-let ((counter 99)) |
这和let看起来非常相像,但并不是暂时的隐藏了全局变量counter的值,而是在fluid-let执行体中临时的将全局变量counter的值设置为了99直到执行体结束。因此执行体中的三句display产生了结果
1 | 100 |
当fluid-let表达式计算结束后,全局变量counter会恢复成之前的的值。
注意fluid-let和let的效果完全不同。fluid-let不会和let一样产生一个新的变量。它会修改已经存的变量的值绑定,当fluid-let结束时这个修改也会结束。
4.8. 递归
一个过程体中可以包含对其它过程的调用,特别的是也可以调用自己。
1 | (define factorial |
这个递归过程用来计算一个数的阶乘。如果这个数是0,则结果为1。对于任何其它的值n,这个过程会调用其自身来完成n-1阶乘的计算,然后将这个子结果乘上n并返回最终产生的结果。
互递归过程也是可以的。下面判断奇偶数的过程相互进行了调用。
1 | (define is-even? |
这里提供的两个过程的定义仅作为简单的互递归示例。Scheme已经提供了简单的判断过程even?和odd?。
4.8.1. letrec
如果希望将上面的过程定义为局部的,我们需要使用letrec结构。
1 | (letrec ((local-even? (lambda (n) |
用letrec创建的词法变量不仅可以在letrec执行体中可见而且在初始化中也可见。letrec是专门为局部的递归和互递归过程而设置的。(这里也可以使用define来创建两个子结构的方式来实现局部递归)
4.8.2. 命名let
使用letrec定义递归过程可以实现循环。如果我们想显示10到1的降数列,可以这样写:
1 | (letrec ((countdown (lambda (i) |
这会在控制台上输出10到1,并会返回结果liftoff。
Scheme允许使用一种叫“命名let”的let变体来更简洁的写出这样的循环:
1 | (let countdown ((i 10)) |
注意在let的后面立即声明了一个变量用来表示这个循环。这个程序和先前用letrec写的程序是等价的,可以将“命名let”看成一个对letrec结构进行扩展的宏。
4.8.3. 迭代
上面定义的countdown函数事实上是一个递归的过程。Scheme只有通过递归才能定义循环,不存在特殊的循环或迭代结构。
尽管如此,上述定义的循环是一个“真”循环,与其他语言实现它们的循环的方法完全相同。也就是说,Scheme十分注意确保上面使用过的递归类型不会产生过程调用/返回开销。
Scheme通过一种消除尾部调用(tail-call elimination)的过程完成这个功能。如果你注意观察countdown的步骤,你会注意到当递归调用出现在countdown主体内时,就变成了“尾部调用”,或者说是最后完成的事情——countdown的每次调用要么不调用它自身,要么当它调用自身时把这个动作留在最后。对于一个Scheme语言的实现来说(解释器),这会使递归不同于迭代。因此,尽管用递归去写循环吧,这是安全的。
这是又一个有用的尾递归程序的例子:
1 | (define list-position |
list-position发现了o对象在列表l中第一次出现的索引。如果在列表中没有发现对象,过程将会返回#f。
这又是一个尾部递归过程,它将自身的参数列表就地反转,也就是使现有的列表内容产生变异,而没有分配一个新的列表:
1 | (define reverse! |
reverse!是一个十分有用的过程,它在很多Scheme方言中都能使用。
4.8.4. 用自定义过程映射整个列表
有一种特殊类型的迭代,对列表中每个元素,它都会重复相同的动作。Scheme为这种情况提供了两种程序:map和for-each。
map程序为给定列表中的每个元素提供了一种既定程序,并返回一个结果的列表。例如:
1 | (map add2 '(1 2 3)) |
for-each程序也为列表中的每个元素提供了一个程序,但返回值为空。
1 | (for-each display |
这个由map和for-each用在列表上的程序并不一定是单参数程序。举例来说,假设一个n参数的程序,map会接受n个列表,每个列表都是由一个参数所组成的集合,而map会从每个列表中取相应元素提供给程序。例如:
1 | (map cons '(1 2 3) '(10 20 30)) |
4.9. 输入输出
Scheme的输入/输出程序,可以从输入端口读取或者写入到输出端口。端口可以关联到控制台,文件和字符串。
4.9.1. 读取
Scheme的读取程序带有一个可选的输入端口参数。如果端口没有特别指定,则默认为当前端口(一般是控制台)。
读取的内容可以是一个字符,一行数据或是S表达式。当每次执行读取时,端口的状态就会改变,因此下一次就会读取当前已读取内容后面的内容。如果没有更多的内容可读,读取程序将返回一个特殊的数据(文件结束符或EOF对象),这个对象只能用eof-object?函数来判断。
read-char程序会从端口读取下一个字符。read-line程序会读取下一行数据,并返回一个字符串(不包括最后的换行符),read程序则会读取下一个S表达式。
4.9.2. 写入
Scheme的写入程序接受一个要被写入的对象和一个可选的输出端口参数。如果未指定端口,则默认为当前端口(一般为控制台)。
写入的对象可以是字符或是S表达式。
write-char程序可以向输出端口写入一个给定的字符(不包括#\)。
write和display程序都可以向端口写入一个给定的S表达式,唯一的区别是:write程序会使用机器可读型的格式而display程序却不用。例如,write用双引号表示字符串,用#\句法表示字符,但display却不这么做。
newline程序会在输出端口输出一个换行符。
4.9.3. 文件端口
如果端口是标准的输入和输出端口,Scheme的I/O程序就不需要端口参数。但是,如果你明确需要这些端口,则current-input-port和current-output-port这些零参数程序会提供这个功能,例如:
1 | (display 9) |
拥有相同的效果。
一个端口通过打开文件和这个文件关联在一起。open-input-file程序会接受一个文件名作为参数,并返回一个和这个文件关联的新的输入端口。open-output-file程序会接受一个文件名作为参数,并返回一个和这个文件关联的新的输出端口。如果打开一个不存在的输入文件,或者打开一个已经存在的输出文件,程序都会出错。
已经在一个端口执行完输入或输出后,需要使用close-input-port或close-output-port程序将它关闭。
在下述例子中,假如文件io.txt文件只包含一个单词hello。
1 | (define i (open-input-file "io.txt")) |
假如文件greeting.txt在下述程序运行前不存在:
1 | (define o (open-output-file "greeting.txt")) |
现在greeting.txt文件将会包含“hello world”。
文件端口的自动打开和关闭
Scheme提供了call-with-input-file和call-with-output-file过程,这些过程会照顾好打开的端口并在你使用完后将端口关闭。
call-with-input-file程序接受一个文件名参数和一个过程。这个过程被应用在一个已打开的文件输入端口。当程序结束时,它的结果会在保证端口关闭后返回。
1 | (call-with-input-file "io.txt" |
call-with-output-file程序会对输出文件提供类似的服务。
4.9.4. 字符串端口
一般来说将字符串与端口相关联是很方便的。因此,open-input-string程序将一个给定的字符串和一个端口关联起来。读取这个端口的程序将读出下述字符串:
1 | (define i (open-input-string "hello world")) |
open-output-string创建了一个输出端口,最终可以用于创建一个字符串:
1 | (define o (open-output-string)) |
现在你可以使用get-output-string程序得到保留在字符串端口o中的字符串:
1 | (get-output-string o) |
字符串端口不需要显式地去关闭。
4.9.5. 加载文件
load程序可以加载包含Scheme代码的文件,load一个文件意味着按顺序求值文件中每一个Scheme表达式。load中的路径参数是相对当前Scheme工作目录计算的,该工作目录一般是调用Scheme可执行文件时的目录。
一个文件可以加载其他的文件,这在包含许多文件的大项目中十分有用。但是,除非使用绝对路径,否则load参数中的文件位置将依赖于执行Scheme的当前目录。而提供绝对路径名并不是很方便,因为我们更愿意把项目文件作为一个单元(保留它们的相对路径名)在很多不同机器中运行。
4.10. 宏
在Scheme中,对宏的处理与C语言类似,也分为两步:第一步是宏展开,第二步则是编译展开之后的代码。这样,通过宏和基本的语言构造,可以对Scheme语言进行扩展——C语言的宏则不具备扩展语言的能力。
宏通过define-macro来定义。例如,如果你的Scheme缺少条件表达式when,你就可以以下述宏定义when:
1 | (define-macro when |
这样定义的when转换器能够把一个when表达式转换为等价的if表达式。
1 | (when (< (pressure tube) 60) |
上面的when表达式,在宏展开后为:
1 | (apply |
这个转换产生了一个列表:
1 | (if (< (pressure tube) 60) |
Scheme将会对这个表达式进行求值,就像它对其他表达式所做的一样。
再来看unless的宏定义:
1 | (define-macro unless |
另外,我们可以调用when放进unless定义中:
1 | (define-macro unless |
宏表达式可以引用其他的宏。
4.11. 结构
我们可以使用Scheme提供的复合数据结构(如向量和列表),来表示一种“结构”。例如:我们正在处理与树木相关的一组数据。数据中的元素包括:高度,周长,年龄,树叶形状和树叶颜色共5个字段。这样的数据可以表示为5元向量,这些字段可以利用vector-ref访问,或使用vector-set!修改。
我们使用Scheme的宏defstruct去定义一个结构,基本上你可以把它当作一种向量,不过它提供了很多方法诸如创建结构实例、访问或修改它的字段等等。因此,我们的树结构应这样定义:
1 | (defstruct tree height girth age leaf-shape leaf-color) |
这样它自动生成了一个名为make-tree的构造过程,以及每个字段的访问方法,命名为tree.height,tree.girth等等。构造方法的使用方法如下:
1 | (define coconut |
这个构造函数的参数以成对的形式出现,字段名后面紧跟着其初始值。这些字段能以任意顺序出现,或者不出现——如果字段的值没有定义的话。
访问过程的调用如下所示:
1 | (tree.height coconut) => 30 |
tree.girth存取程序返回一个未定义的值,因为我们没有为coconut这个tree结构指定girth的值。
修改过程的调用如下所示:
1 | (set!tree.height coconut 40) |
如果我们现在重新调用访问过程去访问这些字段,我们会得到新的值:
1 | (tree.height coconut) => 40 |
4.11.1. 默认初始化
我们可以在定义结构时进行一些初始化的设置,而不是在每个实例中都进行初始化。因此,我们假定leaf-shape和leaf-color在默认情况下分别为frond和green。我们可以在调用make-tree时通过显式的初始化来覆盖掉这些默认值,或者在创建一个结构实例后使用上面提到的字段修改过程:
1 | (defstruct tree height girth age |
4.12. 关联表
关联表是Scheme一种特殊形式的列表。列表的每一个元素都是一个点对,其中的car(左边的元素)被称为键,cdr(右边的元素)被称为和该键关联的值。例如:
1 | ((a . 1) (b . 2) (c . 3)) |
4.13. 系统接口
Scheme程序经常需要与底层操作系统进行交互。
4.13.1. 检查和删除文件
file-exists?会检查它的参数字符串是否是一个文件。delete-file接受一个文件名字符串作为参数并删除相应的文件。这些程序并不是Scheme标准的一部分,但是在大多数Scheme实现中都能找到它们。用这些过程操作目录(而不是文件)并不是很可靠,操作结果与具体的Scheme实现有关。
file-or-directory-modify-seconds过程接受一个文件名或目录名为参数,并返回这个目录或文件的最后修改时间。时间是从格林威治标准时间1970年1月1日0点开始记时的。例如:
1 | (file-or-directory-modify-seconds "hello.scm") |
假定hello.scm文件最后一次修改的时间是1998年4月21日的某个时间。
4.13.2. 调用操作系统命令
system函数把它的参数字符串当作操作系统命令来执行。如果命令成功执行并返回0,则它会返回真,如果命令执行失败并返回某非0值,则它会返回假。命令产生的任何输出都会进入标准的输出。
1 | (system "ls") |
最后两个命令等价于:
1 | (file-exists? fname) |
4.13.3. 环境变量
过程getenv返回操作系统环境变量的设定值,如:
1 | (getenv "HOME") |
4.14. 对象和类
http://www.kancloud.cn/wizardforcel/teach-yourself-scheme/147175
5. 源码分享
https://github.com/voidking/scheme-start.git