1. Spark简介
Spark是一个大数据处理框架,可以进行分片计算和并行计算。和MapReduce相比,计算速度更快,编程模型更简单易用。
当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据),这时我们可以选择spark集群进行计算。
有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择利用spark集群强大的计算资源,并行化地计算。
详情参考:
2. Spark架构
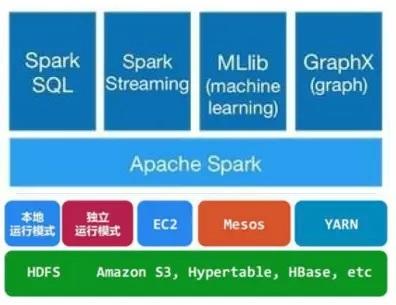
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
- HDFS:分布式文件系统。spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS。
3. Spark执行流程
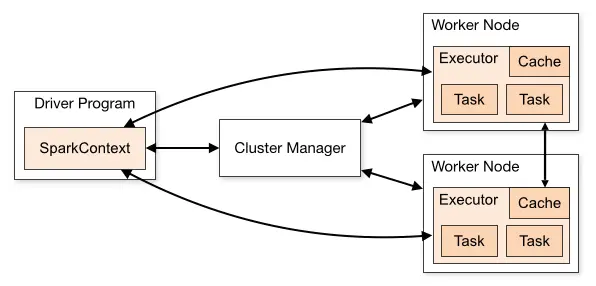
Spark 支持 Standalone、Yarn、Mesos、Kubernetes 等多种部署方案,几种部署方案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。
首先,Spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位也就是计算任务。
然后 Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
Worker 收到信息以后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
4. Spark部署模式
本节内容来自chatgpt。
Apache Spark 可以运行在不同的部署模式下,以满足不同的需求。以下是一些常见的 Spark 部署模式:
- Local 模式:在单个 JVM 进程中运行,主要用于开发和测试。
- Standalone 模式:在 Spark 自带的资源管理器下运行,适用于中小规模集群。
- Apache Mesos 模式:在 Mesos 集群上运行,可以与其他框架共享硬件资源。
- Hadoop YARN 模式:在 Hadoop YARN 集群上运行,可以与其他 Hadoop 应用程序共享资源。
- Kubernetes 模式:在 Kubernetes 集群上运行,可以与其他容器化应用程序共享硬件资源。
Spark 还支持各种云环境中的部署,例如 Amazon EMR、Microsoft Azure 和 Google Cloud Platform 等。在这些环境中,Spark 集成了相应的管理工具,使得部署更加简单。