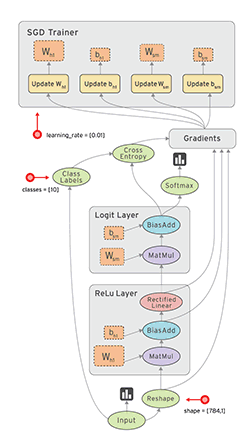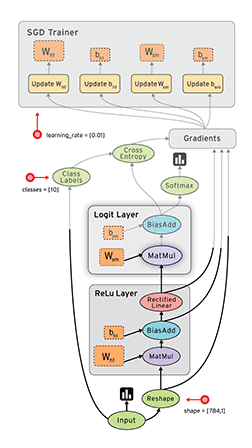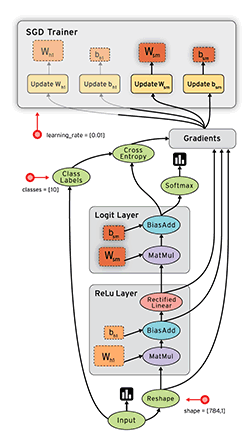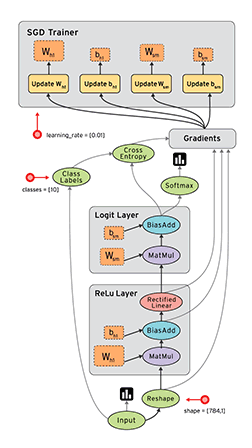
""" Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
with tf.Session() as sess: # once define variables, you have to initialize them by doing this sess.run(init) for _ in range(3): sess.run(update_operation) print(sess.run(var))
defadd_layer(inputs, in_size, out_size, activation_function=None): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, Weights) + biases if activation_function isNone: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs
# Make up some real data x_data = np.linspace(-1,1,300)[:, np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise
# the error between prediction and real data loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# important step init = tf.global_variables_initializer() sess = tf.Session() sess.run(init)
for i inrange(1000): # training sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: # to see the step improvement print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt
defadd_layer(inputs, in_size, out_size, activation_function=None): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, Weights) + biases if activation_function isNone: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs
# Make up some real data x_data = np.linspace(-1,1,300)[:, np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise
# the error between prediction and real data loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# important step init = tf.global_variables_initializer() sess = tf.Session() sess.run(init)