1. 阿里云
据Gartner发布的2017年度全球公有云市场份额分析报告,全球范围内的公有云市场已经形成了3A格局:亚马逊AWS、微软Azure、阿里云AliYun。
今年,天猫双11以2135亿的成交额再破记录。这背后,是阿里云的技术在支撑,阿里云的大数据计算平台已经拥有全世界最牛的大数据并发处理能力。
本文,就来研究整理一下阿里云的技术栈。
2. 历史
2009年之前IOE(IBM小型机,Oracle数据库,EMC存储设备),Oracle之巅。
2009年9月阿里云成立,愿景是要做一套大数据分布式计算/存储的云平台,自主研发飞天体系,包括三大部分:底层的分布式存储系统——盘古、分布式调度系统——伏羲、开放数据处理服务——ODPS(Open Data Processing Service)。后来又添加了集群诊断系统——华佗、网络连接模块——夸父、监控系统——神农、集群部署——大禹。
2009-2011年期间云梯1(Hadoop)、云梯2(飞天),两套系统,云梯1承载初期集团淘宝的数据业务,云梯2助力阿里金融的第一个产品“牧羊犬”应用上线。
2011年,集团主要业务全部登上云梯1,阿里构建了国内领先的hadoop集群。两座云梯同时发展,开始进行博弈,规则很明确:要想成功肩负起阿里巴巴的底层计算系统,就必须有能力独自调度5000台服务器,“赢者通吃”,继承家业。
2011年,大数据实时计算发展也随业务而生。数据魔方研发了第一个版本的galaxy,b2b搜索团队也研发了一个叫iprocess的流计算系统。在12年7月份,数据平台事业部(CDO)成立,两个团队走到了一起组建了实时计算团队。
2012年冰火鸟:数据业务层统一。云梯1、云梯2运维团队合并。
2013年5K之战:突破集群存储的瓶颈。云梯2突破5K。
2014年-2015年登月计划:打造集团统一大数据平台。云梯1停止,云梯2成为集团统一的大数据平台。ODPS更名为“MaxCompute”。
2015年,支持公有云,阿里大数据计算能力,走出集团服务全球。
2016年,建设主备双链路容灾、实时全链路监控、Tesla运维诊断工具实时全链路保障方案。大力发展实时计算,Galaxy、JStorm和Search dump三支实时计算团队资源整合。
2017年,MaxCompute架构升级,在NewSQL、富结构化、联合计算平台、AliORC多个方向上发力,继续构建高可用、高性能、高自适性的一站式的大数据解决方案开放平台。
更详细历史,参考首次探秘!双11奇迹背后的大数据力量,十年发展五部曲。
阿里大数据技术如何进化?资深技术专家带你回顾一文中作者观滔提到:
如果把阿里巴巴整体数据体系比作这个战队,那么MaxCompute就是中间的那艘航空母舰,几乎阿里巴巴99%的数据存储以及95%的计算能力都在这个平台上产生。
3. 计算平台
阿里的计算平台服务主要有MaxCompute、流计算Blink、图计算FLASH、机器学习PAI。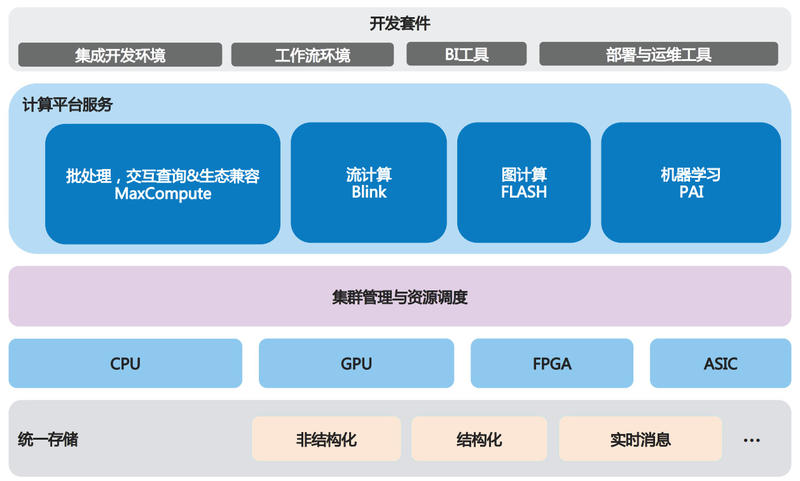
3.1. MaxCompute
由历史可以看出,现在的阿里技术核心围绕MaxCompute。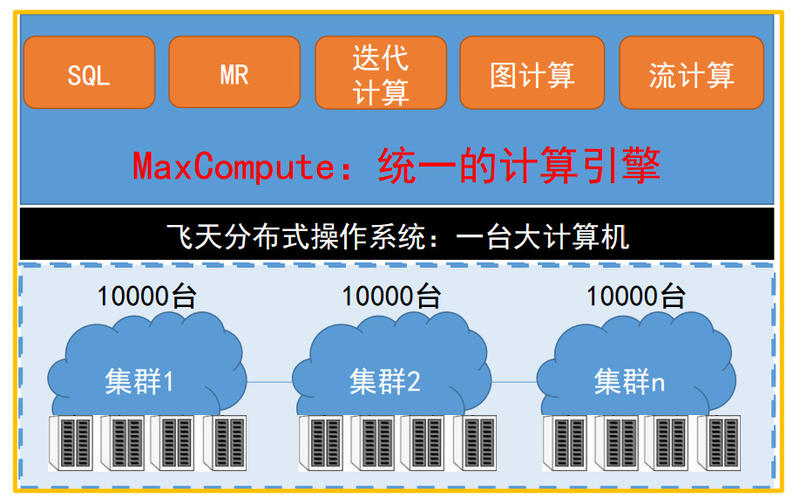
上图是MaxCompute的技术架构。最下面一层是物理机器,MaxCompute有自己的物理集群,在集群之上有非常重要的能力:它把一个集群组织成了1万台计算机,MaxCompute 2.0很大的特性是集群能力得到了扩展,从5千变成了1万。黑色部分是飞天操作系统,提供整个分布式系统任务协同、资源管理、集群调度等功能,为上层云产品提供统一的操作系统服务。其上是MaxCompute统一的计算引擎,支持SQL、MR、迭代计算、图计算、流计算。
详情参考阿里巴巴大数据计算平台MaxCompute(原名ODPS)全套攻略和性能追求之路——MaxCompute2.0(原ODPS)的前世今生。
3.2. Blink
Apache Flink是面向数据流处理和批处理的分布式开源计算框架,2016年阿里巴巴引入Flink框架,改造为Blink。2017年,阿里整合了所有流计算产品,决定以Blink引擎为基础,打造一款全球领先的实时计算引擎。当年双11,Blink支持了二十多个事业部/群,同时运行了上千个实时计算job,每秒处理的日志数峰值达到惊人的4.7亿。
详情参考阿里新一代实时计算引擎 Blink,每秒支持数十亿次计算。
3.3. FLASH
FLASH是阿里的图计算平台。简单的说图计算就是研究在大规模图数据下,如何高效计算,存储和管理图数据等相关问题的领域。
应用:搜索推荐、关联分析、实时预测等。
详情参考FLASH:大规模分布式图计算引擎及其应用和大规模图计算系统综述。
3.4. PAI
PAI是阿里自己的智能平台,该平台基于阿里云的云计算平台,具有处理超大规模数据的能力和分布式的存储能力,同时整个模型支持超大规模的建模以及GPU计算。此外,该平台还具有社区的特点:实验结果可共享、社区团队相互协作。该智能平台主要分为三层,第一层是Web UI界面,第二层是IDST算法层,最后一层是ODPS平台层。
详情参考阿里云机器学习平台——PAI平台。
4. 技术架构
除了MaxCompute,阿里还有很多其他的技术,如下图: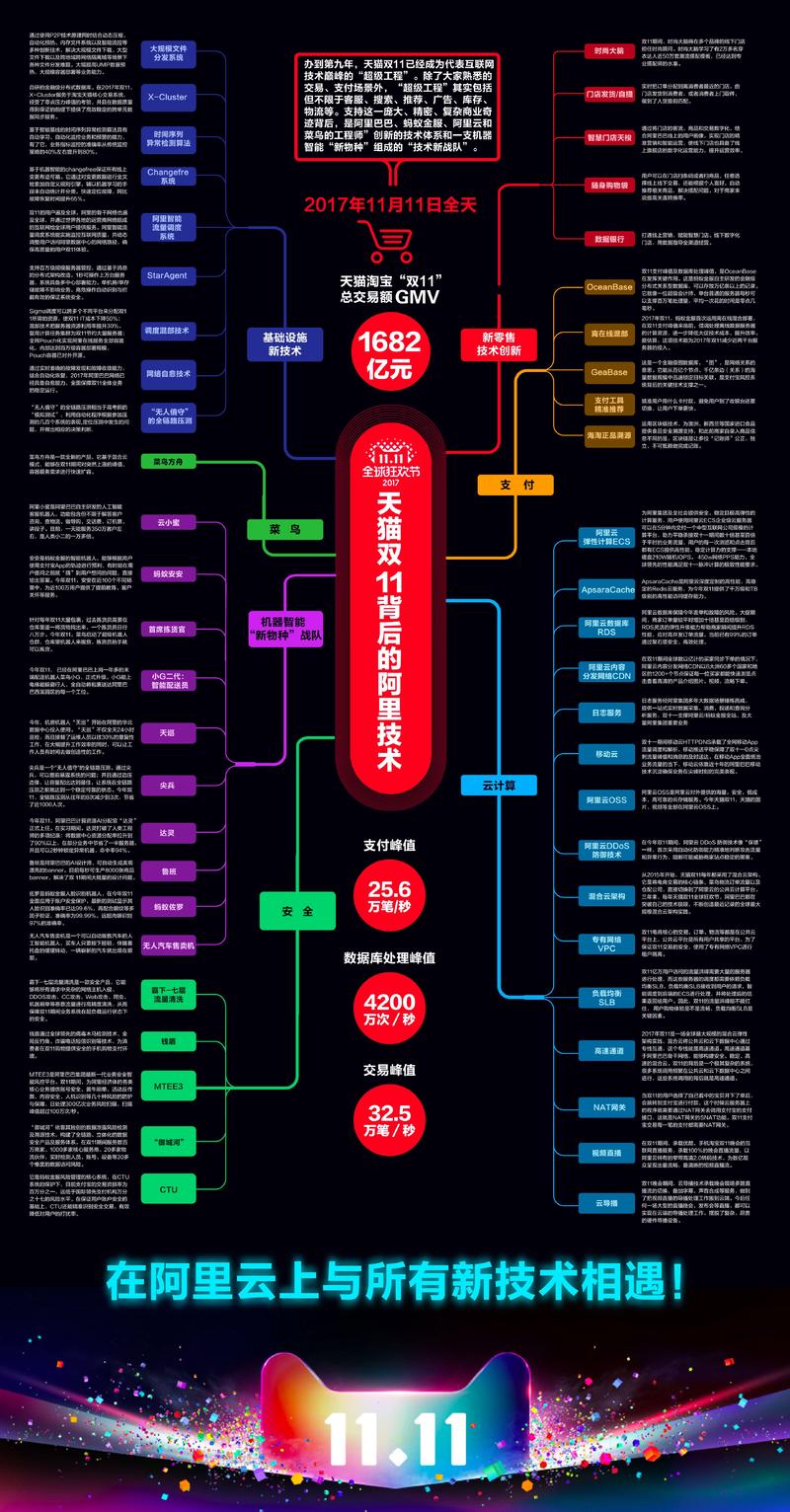
1、基础设施新技术
大规模文件分发系统、X-Cluster、时间序列异常检测算法、Changefre系统、阿里智能流量调度系统、StarAgent、调度混部技术、网络自愈技术、“无人值守”的全链路压测
2、新零售技术创新
时尚大脑、门店发货/自提、智慧门店天梭、随身购物袋、数据银行
3、菜鸟
菜鸟方舟
4、支付
OceanBase、离在线混部、GeaBase、支付工具精准推荐、海淘正品溯源
5、机器智能“新物种”战队
云小蜜、蚂蚁安安、首席拣货官、小G二代:智能配送员、天巡、尖兵、达灵、鲁班、蚂蚁佐罗、无人汽车售卖机
6、云计算
阿里云弹性计算ECS、ApsaraCache、阿里云数据集RDS、阿里云内容分发网络CDN、日志服务、移动云、阿里云OSS、阿里云DDoS防御技术、混合云架构、专有网络VPC、负载均衡SLB、高速通道、NAT网关、视频直播、云导播
7、安全
霸下——七层流量清洗、钱盾、MTEE3、御城河、CTU
5. 技术点
5.1. 调度混部技术
Sigma通过和离线任务的伏羲调度系统深度集成,突破了若干CPU、内存和网络资源隔离的关键技术,实现了在线和离线任务的混合部署。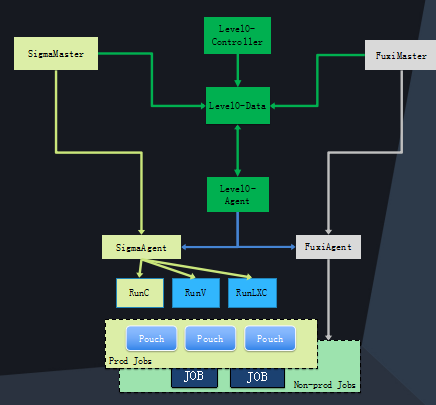
Sigma调度可以跨多个不同平台来分配双11所需的资源,使双11 IT成本下降50%;混部技术把服务器资源利用率提升30%,复用计算任务集群为双11节约大量服务器。
在线服务的容器就像砖块,而计算任务就像沙子和水。当在线服务压力小的时候,计算任务就占住那些空隙,把空闲的资源都使用起来,而当在线服务忙的时候,计算任务便立即退出空隙,把资源还给在线服务。
详情参考想了解阿里巴巴的云化架构 看这篇就够了。
5.2. Pouch容器
阿里的容器技术经历了一个从集中式到分布式架构上的演化,最开始是直接跑在物理机上,之后引入了虚拟化技术,但整体的资源使用率不高,因而过渡到了容器技术。2015 年以后,阿里巴巴引入Docker标准,形成一套新的容器技术——Pouch,并集成到整个运维体系。
全网Pouch化实现阿里在线服务全部容器化,内部达到百万级容器部署规模,Pouch容器已对外开源。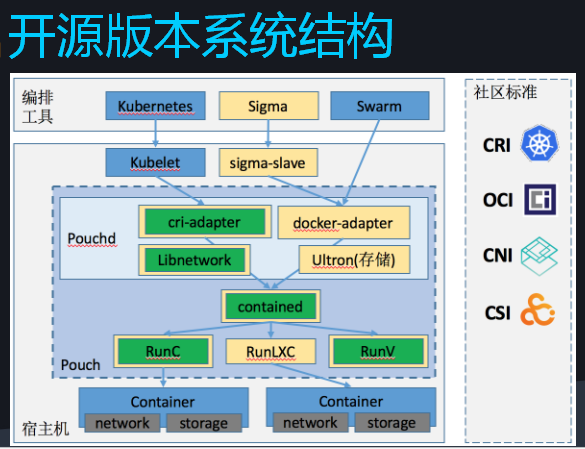
5.3. 全链路压测
阿里巴巴双11备战期间,保障系统稳定性最大的难题在于容量规划,而容量规划最大的难题在于准确评估从用户登录到完成购买的整个链条中,核心页面和交易支付的实际承载能力。
最初采用的方式是在线上单机的生产环境的压力测试和容量规划,基于单台服务能力和预估即将到来的业务流量进行容量规划,确定所需服务器的数目。
2010-2012年双11暴露了不少问题,单个系统ready不代表全局ready,究其根本原因在于系统之间相互关联和依赖调用之间相互影响。在做单个系统的容量规划时,所有的依赖环节能力是无限的,进而使得获取的单机能力值是偏乐观的;同时,采用单系统规划时,无法保证所有系统均一步到位,大多数精力都集中核心少数核心系统;此外,部分问题只有在真正大流量下才会暴露,比如网络带宽等等。
阿里从13年起着手进行全链路压测。全链路压测的本质是让双11零点这一刻提前在系统预演(用户无感知),模拟“双11”同样的线上环境、用户规模、业务场景、业务量级,之后再针对性地进行系统调优,是站点的一次高仿真模拟考试。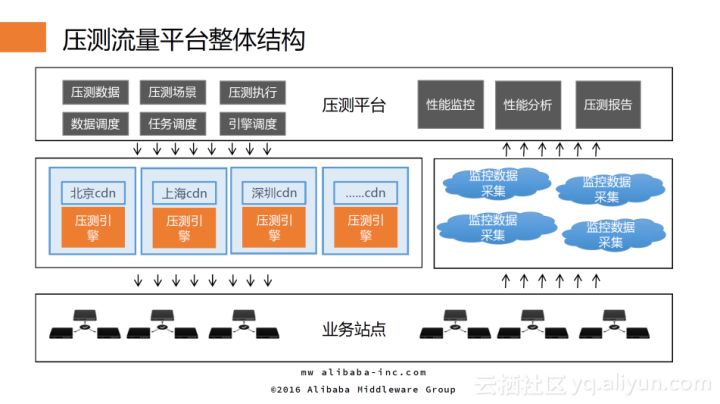
全链路压测核心要素主要包括四点:
- 压测环境,它是指具备数据与流量隔离能力的生产环境,不能影响到原有的用户体验和用户流程、BI报表以及推荐算法等;
- 压测基础数据,它主要包括压测用户、店铺、商品等基础数据;
- 压测场景模型,它主要是指压测哪些业务场景,每个场景下压测多大量等;
- 压测流量,它主要由压测请求的协议来决定压测流量的输出
详情参考系统稳定性保障核武器——全链路压测。
5.4. OceanBase
OceanBase是阿里完全自主研发的金融级分布式关系数据库,从架构上可以通过扩展机器来解决集群服务能力的扩展需求。OceanBase采用多副本复制的方案解决了可靠性和可用性的需求,而且构建在普通PC服务器上,不依赖于高端引擎。
OceanBase从诞生、到电商数据库、再到金融数据库及最终的云数据库,经历了四个阶段。
详情参考阿里蚂蚁金服的关系型数据库:OceanBase架构详解和OceanBase 2.0 到底如何做到 50% 的性能提升?。
5.5. Dubbo
Dubbo是阿里巴巴于 2012 年开源的分布式服务治理框架,目前已是国内影响力最大、使用最广泛的开源服务框架之一,在Github上的 fork、star数均已破万。
Dubbo 致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案,使得应用可通过高性能RPC 实现服务的输出和输入功能, 和 Spring 框架无缝集成。Dubbo包含远程通讯、集群容错和自动发现三个核心部分。提供透明化的远程方法调用,实现像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。
同时具备软负载均衡及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。可以实现服务自动注册与发现,不再需要写死服务提供方地址,注册中心基于接口名查询服务提供者的 IP 地址,并且能够平滑添加或删除服务提供者。
详情参考分布式服务框架Dubbo疯狂更新!阿里开源要搞大事情?。
5.6. StarAgent
StarAgent 是一个生态平台。阿里所有的物理机、虚拟机以及容器都会装StarAgent,基本上要和机器交互都需要通过这个平台。它实际上不会做具体的业务,具体的业务还是通过各个业务平台去实现的。
StarAgent 核心功能就是一个命令的通道,它既可以同步执行任务又可以异步执行任务,还可以查询任务状态和插件管理。插件分为两种,一种是静态的,静态的实际上就是脚本、命令之类的。另一种动态的是一个常驻进程,必须常驻在系统里面。我们会守护这个进程,如果它挂了会重新拉起来,如果其占用内存、CPU超过设定的范围会删掉它。整个协议是比较简单的,使用起来耦合度也是比较低的。
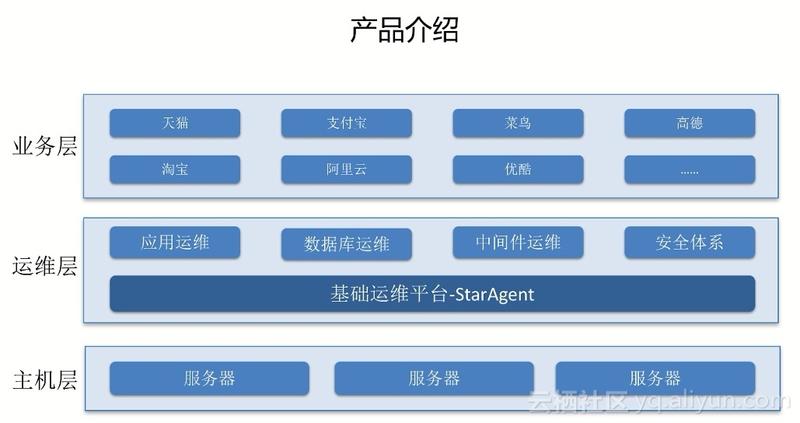
详情参考双11黑科技,阿里百万级服务器自动化运维系统StarAgent揭秘、阿里巴巴运维中台的演进与建设、阿里巴巴运维中台的演进与建设ppt。
5.7. 蜻蜓
蜻蜓系统是纯碎的 P2P 的文件分发系统。
详情参考阿里巴巴运维中台的演进与建设。
5.8. Normandy
Normandy 是运维整个阿里巴巴业务的PaaS平台。这个平台实际上提供三大功能,分别是基础设施即代码(Infrastructure as Code)、部署和应用运维支撑。
详情参考阿里巴巴运维中台的演进与建设。