1. 前言
《在Ubuntu16.04上安装Hadoop》一文中,搭建好了hadoop平台。
接下来,我们参照慕课网Kit_Ren的《Hadoop大数据平台架构与实践——基础篇》教程,跑一下单词计数程序。
要求:计算文件中出现每个单词的频数,输入结果按照字母顺序进行排序。
输入:
1 | hello world bye world |
输出:
1 | bye 3 |
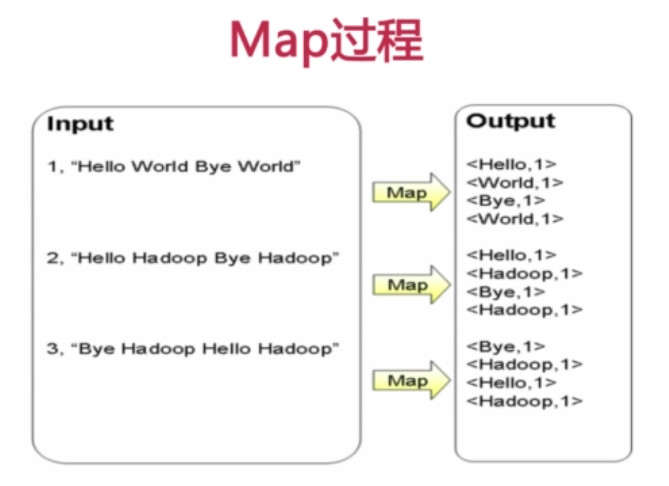
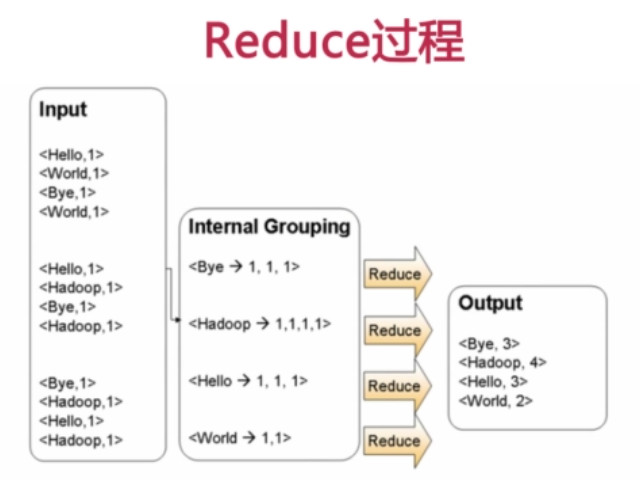
2. MapReduce过程
3. 编译打包和运行
1、上传 WordCount.java 文件到hadoop所在机器
2、编译java文件
1 | javac -classpath /opt/hadoop-1.2.1/hadoop-core-1.2.1.jar:/opt/hadoop-1.2.1/lib/commons-cli-1.2.jar WordCount.java |
3、打包三个.class文件为一个jar文件
1 | jar -cvf wordcount.jar *.class |
4、新建两个文件,file1和file2,内容分别为:
1 | hello world bye world |
1 | hello world bye world |
5、把file1和file2放到hdfs中
1 | hadoop fs -mkdir wordcount_input |
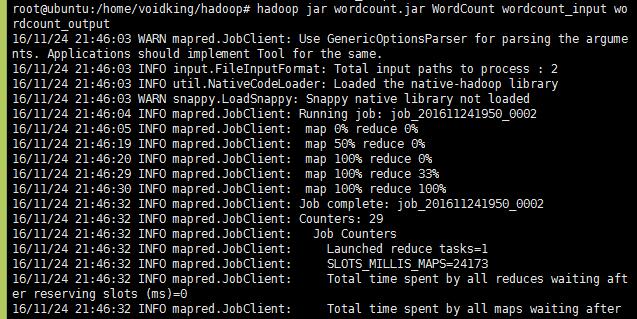
6、执行jar包
1 | hadoop jar wordcount.jar WordCount wordcount_input wordcount_output |
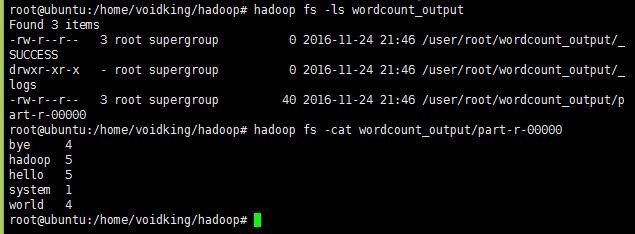
7、查看结果
1 | hadoop fs -ls wordcount_output`,`hadoop fs -cat wordcount_output/part-r-00000 |