1. 功能进阶
1、Java网页爬虫,最基础的功能,是能爬取某个页面的html源码。
2、图形化界面。
3、爬取某个页面的html源码,以及页面需要的静态资源(图片、css和js)。
4、爬取某个页面的html源码,以及页面中的链接指向的页面的html源码,并且不断地延伸爬取。
整个开发过程,需要用到网络编程、正则表达式、I/O流、图形界面编程、事件监听、多线程等。为了简化开发,还需要用到一些外部jar包,比如jsoup。
2. 模块划分
1、获取页面模块:获取页面文档,以及页面文档的字符串。
2、获取页面链接模块:获取页面中存在的各种链接,包括a标签、img标签、css链接、js链接等。
3、获取静态文件模块:静态文件分为两种,一种是字符串类型,一种是字节类型。
4、保存文件模块:保存页面文档和静态文件。
5、界面模块:包括界面设计,事件监听处理。
3. 核心代码摘要
3.1. 获取页面模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class Page {
Document doc = null;
public Page(String url) {
try {
doc = Jsoup.connect(url).timeout(5000).userAgent("Mozilla").get();
} catch (IOException e) {
e.printStackTrace();
}
}
public String getHtml(){
return doc.html();
}
public Document getDoc(){
return doc;
}
}
|
3.2. 获取页面链接模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public class UrlList {
public Document doc = null;
public UrlList(String url) {
try {
doc = Jsoup.connect(url).timeout(5000).userAgent("Mozilla").get();
} catch (IOException e) {
e.printStackTrace();
}
}
public ArrayList<Element> getLinkList(){
Elements links = doc.select("link[href]");
ArrayList<Element> resultList = new ArrayList<Element>();
for(Element link : links){
resultList.add(link);
}
return resultList;
}
public ArrayList<Element> getCssList(){
Elements links = doc.select("link[href]");
ArrayList<Element> resultList = new ArrayList<Element>();
for(Element link : links){
if("stylesheet".equals(link.attr("rel"))){
resultList.add(link);
}
}
return resultList;
}
public ArrayList<Element> getAList(){
Elements links = doc.select("a[href]");
ArrayList<Element> resultList = new ArrayList<Element>();
for(Element link : links){
resultList.add(link);
}
return resultList;
}
public ArrayList<Element> getImgList(){
Elements links = doc.select("img[src]");
ArrayList<Element> resultList = new ArrayList<Element>();
for(Element link : links){
resultList.add(link);
}
return resultList;
}
public ArrayList<Element> getJsList(){
Elements links = doc.select("script[src]");
ArrayList<Element> resultList = new ArrayList<Element>();
for(Element link : links){
resultList.add(link);
}
return resultList;
}
}
|
3.3. 获取静态文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public class Source {
public String getString(String url) {
String result = "";
BufferedReader in = null;
try {
URL realUrl = new URL(url);
URLConnection connection = realUrl.openConnection();
connection.connect();
in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
} finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
}
|
3.4. 保存文件模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
| public class SaveFile {
public void saveFile(String path, String htmlStr) {
File file = new File(path + "\\爬取的文件\\index.html");
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
FileOutputStream fos = null;
try {
fos = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(fos, "UTF-8");
writer.write(htmlStr);
writer.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void saveCss(String path, ArrayList<Element> cssList) {
for (int i = 0; i < cssList.size(); i++) {
if (!cssList.get(i).attr("abs:href").equals(cssList.get(i).attr("href"))) {
Source source = new Source();
String css = source.getString(cssList.get(i).attr("abs:href"));
String paths[] = cssList.get(i).attr("href").split("\\?");
File file = new File(path + "\\爬取的文件\\" + paths[0]);
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
FileOutputStream fos = null;
try {
fos = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(fos, "UTF-8");
writer.write(css);
writer.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
public void saveImg(String path, ArrayList<Element> imgList) {
for (int i = 0; i < imgList.size(); i++) {
if (!imgList.get(i).attr("abs:src").equals(imgList.get(i).attr("src"))) {
String paths[] = imgList.get(i).attr("src").split("\\?");
File file = new File(path + "\\爬取的文件\\" + paths[0]);
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
try {
URL uri = new URL(imgList.get(i).attr("abs:src"));
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(file);
byte[] buf = new byte[1024];
int length = 0;
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
in.close();
fo.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public void saveJs(String path, ArrayList<Element> jsList){
for (int i = 0; i < jsList.size(); i++) {
if (!jsList.get(i).attr("abs:src").equals(jsList.get(i).attr("src"))) {
Source source = new Source();
String css = source.getString(jsList.get(i).attr("abs:src"));
String paths[] = jsList.get(i).attr("src").split("\\?");
File file = new File(path + "\\爬取的文件\\" + paths[0]);
if (!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
FileOutputStream fos = null;
try {
fos = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(fos, "UTF-8");
writer.write(css);
writer.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
|
3.5. 界面模块
代码略,来个图说明设计。
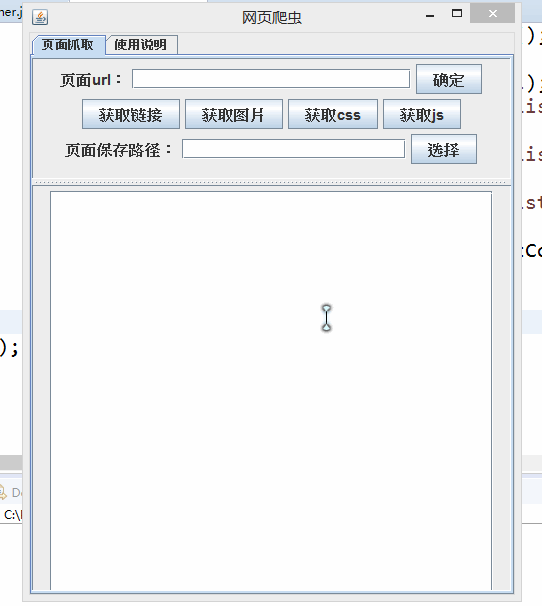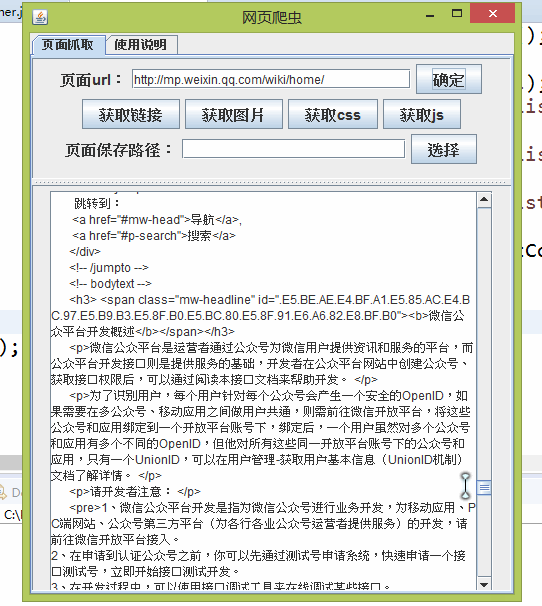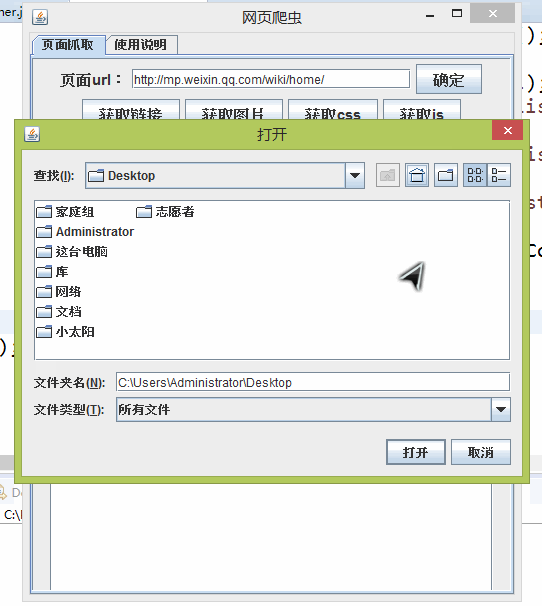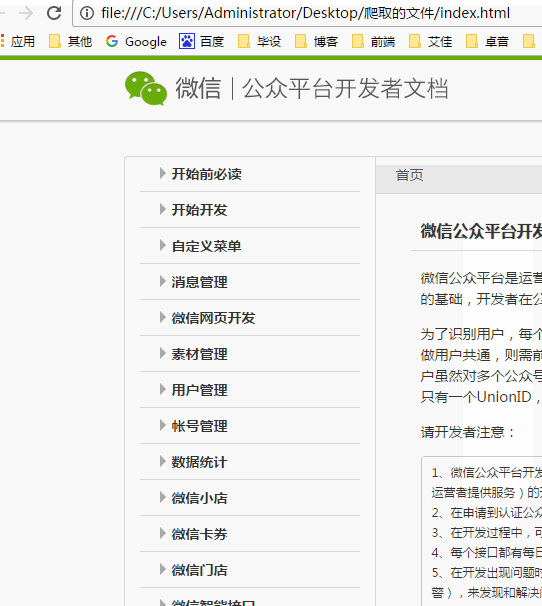
4. 后记
未填的坑:
1、最终设计做到了功能3,功能4未做。
2、爬取文件的相对位置需要另做处理。
5. 源码分享
https://github.com/voidking/java-crawler
6. 书签
如何用Java写一个爬虫?
https://www.zhihu.com/question/30626103
零基础写Java知乎爬虫之先拿百度首页练练手
http://www.jb51.net/article/57193.htm
网页爬虫的设计与实现(Java版)
http://www.aiuxian.com/article/p-2279197.html
网页爬虫系统的设计
http://www.tuicool.com/articles/7JVzIza
专栏:使用JSOUP实现网络爬虫
http://blog.csdn.net/column/details/jsoup.html
jsoup Cookbook(中文版)
http://www.open-open.com/jsoup/