1. 前言
越学习,越发现自己的无知。——笛卡尔
笛卡尔的这句话,用在郝同学学习机器学习的进展,刚好合适。从开始搞机器学习到现在,一年多了,学习了很多课程,查阅了很多文档,阅读了很多书籍,编写了很多代码,然而,并没有什么实质性的进展。没有任何可以拿得出手的成绩,可以让面试官眼前一亮。
寒假了,继续“搞机”,参加kaggle和天池,边比赛边学习,学以致用,为自己书写一份优秀的简历。
接下来一段时间,郝同学会参考七月在线的《Kaggle案例实战班》教程,选择一些项目进行实战。
2. 问题解决流程
1、了解场景和目标
2、了解评估准则
3、认识数据
4、数据预处理(清洗,调权)
5、特征工程
6、模型选择
7、模型调参(选择最佳超参数:交叉验证)
8、模型状态分析
9、模型融合
2.1. 了解场景和目标
1、这是一个什么样的问题?
2、可以采集到哪些数据?
3、需要完成什么样的目标?
2.2. 了解评估标准
https://www.kaggle.com/wiki/Metrics
2.3. 认识数据
编程显示出前几行、前几列,观察特点。
1、数据有哪些维度?
2、数据是不是分布平衡?
3、数据是不是有缺省值?
2.4. 数据预处理
1、数据清洗
- 不可信的样本丢掉
- 缺省值极多的字段考虑不用
2、数据采样
- 上/下采样
- 保证样本均衡(加权)
- bagging,vote
3、工具
- hive sql/spark sql
- pandas
2.5. 特征工程
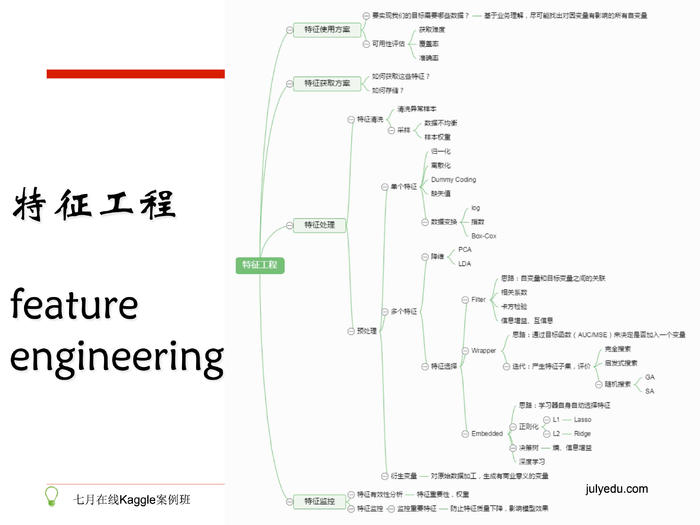
1、特征处理
- 数值型
- 类别型
- 时间类(离散型,间隔型,组合型)
- 文本类(n-gram,bag of words,tf-idf,word2vec)
- 统计型
- 组合特征
2、特征抽取
http://scikit-learn.org/stable/modules/preprocessing.html
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_extraction
3、特征选择
http://scikit-learn.org/stable/modules/feature_selection.html
过滤型:sklearn.feature_selection.SelectKBest
包裹型:sklearn.feature_selection.RFE
嵌入型:feature_selection.SelectFromModel,Linear model,L1正则化
2.6. 模型选择
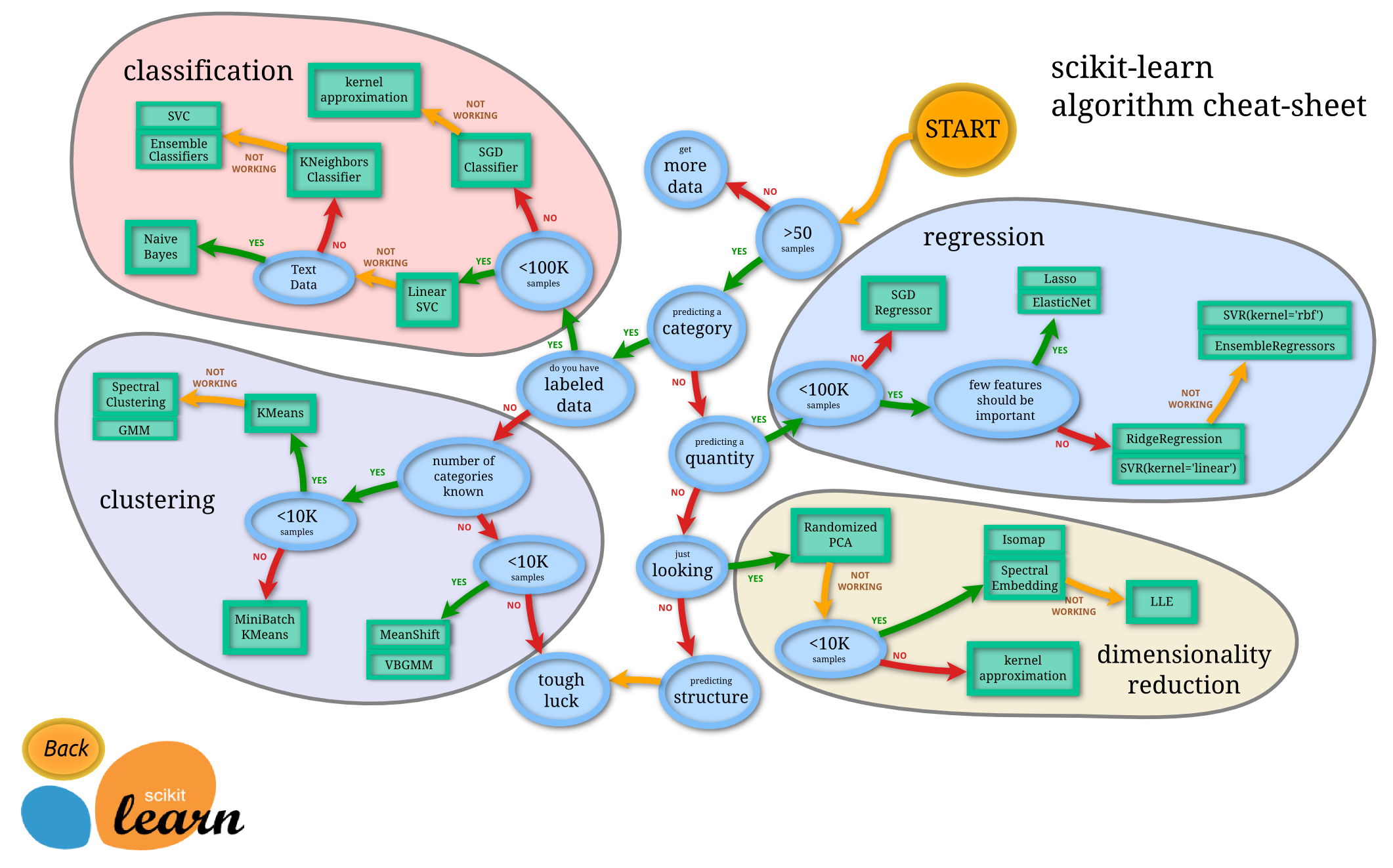
- sklearn cheat-sheet提供的候选
- 课程案例经验
- 交叉验证(cross validation):K折交叉验证(K-fold cross validation)、Cross-validation: evaluating estimator performance
2.7. 模型参数选择
交叉验证:
2.8. 模型状态评估
1、模型状态过拟合还是欠拟合
2、学习曲线(learning curve)
2.9. 模型融合
1、群众的力量是伟大的,集体智慧是惊人的
(1)Bagging
(2)随机森林/Random forest
2、站在巨人的肩膀上,能看得更远
(1)模型stacking
3、一万小时定律
(1)Adaboost
(2)逐步增强树/Gradient Boosting Tree
2.9.1. Bagging
1、模型很多时候效果不好的原因是什么?
(1)过拟合啦!!!
2、如何缓解?
(1)少给点题,别让它死记硬背这么多东西
(2)多找几个同学来做题,综合一下他们的答案
3、sklearn.ensemble.BaggingClassifier
(1)用一个算法
不用全部的数据集,每次取一个子集训练一个模型
分类:用这些模型的结果做vote
回归:对这些模型的结果取平均
(2)用不同的算法
用这些模型的结果做vote 或 求平均
2.9.2. Stacking
用多种predictor结果作为特征训练
2.9.3. Boosting
考得不好的原因是什么?
(1)还不够努力,练习题要多次学习
解决办法:重复迭代和训练
(2)时间分配要合理,要多练习之前做错的题
解决办法:每次分配给分错的样本更高的权重
(3)我不聪明,但是脚踏实地,用最简单的知识不断积累,成为专家
解决办法:最简单的分类器的叠加
3. 原则和技巧
1、画出数据
2、简单实现
3、画出图表
4、根据图表优化
数据的重要性超过模型。
4. 注意点与核心思路
1、拿到数据后怎么了解数据(可视化)
2、选择最贴切的机器学习算法
3、定位模型状态(过/欠拟合)以及解决方法
4、大量级的数据的特征分析与可视化
5、各种损失函数(loss function)的优缺点及如何选择