1. 前言
《虚拟机在线迁移实验》一文中,进行了一些虚拟机迁移实验,并且记录了迁移过程中的指标数据。但是,实验环境是搭建在VirtualBox虚拟机中的,最终的实验结果不理想,会出现停机时间过长,迁移后实例卡住等问题。而且受限于虚拟机的大小,无法创建m1.xlarge这样的大型实例。
最近参照《Ubuntu16使用Kolla安装OpenStack》和《Kolla安装OpenStack多节点》,在物理机环境中重新搭建了OpenStack集群,三个节点分别为controller(network)、compute1、compute2。接下来我们在物理机中重新进行迁移实验,本文记录一下实验的步骤和结果。
2. 实例准备
1、在horizon控制台,项目,计算,镜像。使用xenial-server-cloudimg-amd64-disk1.img镜像创建ubuntu16的镜像模板。
2、创建实例类型m1.tiny2,CPU个数为1,内存为512M,磁盘为5GB。
3、使用ubuntu16的镜像模板创建实例ubuntu0、ubuntu1、ubuntu2、ubuntu3、ubuntu4,实例类型分别选择m1.tiny2、m1.small、m1.medium、m1.large、m1.xlarge。之所以不使用默认的m1.tiny,是因为m1.tiny的磁盘太小,只有1G,无法安装ubuntu16。

4、创建成功后,分别分配浮动IP。
PS:在进行迁移实验时,关闭其他实例,防止资源占用产生干扰。
3. 脚本和软件准备
3.1. 总迁移时间
在两个计算节点,新建total-time.sh脚本:
1 |
|
3.2. 停机时间
在控制节点,新建downtime.sh脚本:
1 |
|
3.3. 迁移数据量
在两个计算节点,安装iptraf-ng。apt install iptraf-ng
3.4. apache
在ubuntu0等实例中安装apache:apt install apache2
安装的默认版本为Apache/2.4.18 (Ubuntu)。
3.5. apachebench
在控制节点,安装apachebench:apt install apache2-utils
在控制节点,新建format.sh脚本:
1 |
|
3.6. xshell
使用xshell,打开3个controller节点的shell,一个用来ping实例,一个用来运行apachebench,一个用来执行迁移命令。打开2个compute1节点的shell,一个用来运行iptraf-ng,一个用来执行total-time.sh脚本。打开2个compute2节点的shell,一个用来运行iptraf-ng,一个用来执行total-time.sh脚本。
4. 实验流程
假设当前只启动了ubuntu0实例,nova show ubuntu0位于compute1节点。
1、在实例中启动压力测试软件,或者在两个compute节点中启动网络故障模拟软件。(flavor实验中不需要)
2、在两个compute节点启动iptraf-ng,配置参考《虚拟机在线迁移的性能统计》。
3、在三个controller的shell中分别输入好一条命令:
1 | sudo ping 172.16.0.19 -i 0.001 >> ping.log |
然后,依次回车执行这些命令。
4、观察compute节点的iptraf-ng,等到流量不再增加,Ctrl+C结束ping命令。
5、在controller节点执行downtime.sh得到停机时间,在compute1节点执行total-time.sh得到迁移时间,在两个计算节点观察iptraf-ng得到迁移数据量。
6、等到ab命令结束,执行./format.sh t0.dat,得到吞吐量数据ff-t0.dat。
以上流程,适用于接下来的所有实验。
5. flavor实验
1、按照实验流程,分别使用五个flavor,进行五次迁移实验,记录实验结果。
1 | #Flavor 迁移时间s 停机时间ms 迁出数据量MB 迁入数据量MB |
2、同时得到五个吞吐量数据文件,ff-t0.dat到ff-t4.dat。
6. 吞吐量问题
实验结果绘图,发现五种flavor的吞吐量基本没有差别!都是800上下。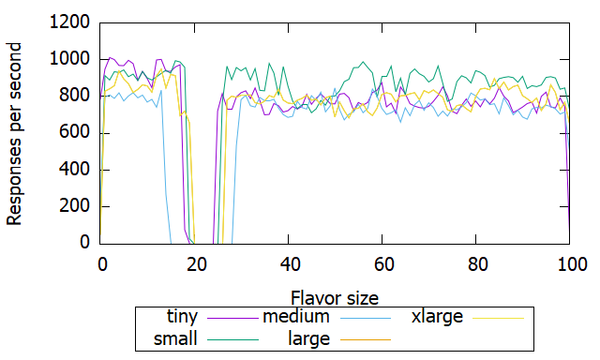
为了解决apache吞吐量问题,必须得研究一下。
6.1. 修改apache配置
思路一:提高apache的最大连接数。参考如何设置Apache中的最大连接数、如何设置Apache中的最大连接数。
1、查看apache moduleapachectl -V
可以看到Server MPM为event。如果要换成其他MPM,可以参考Ubuntu配置apache2.4的限速功能进行设置,比如换成prefork,这里我们不进行更换。
1 | cd /etc/apache2/mods-enabled |
2、备份配置
1 | cd /etc/apache2/mods-available/ |
3、修改配置
编辑/etc/apache2/mods-available/mpm_event.conf,原文件为:
1 | # event MPM |
参考关于apache的mpm-event的参数无法调整问题,修改为:
1 | <IfModule mpm_event_module> |
MaxSpareThreads的参数设置,需要根据StartServers*ThreadsPerChild=1000,因此MaxSpareThreads必须大于1000,在此为1200,否则会有StartServers-MaxSpareThreads/ThreadsPerChild个进程被杀掉。
MaxRequestWorkers的参数设置,需要根据ServerLimit*ThreadsPerChild=5000,否则启动会有警告。
4、重启apache2sudo service apache2 restart
然而,并没有用,吞吐量并没有发生什么变化,依然是800左右,不过波动幅度变大了。MPM更换为prefork,吞吐量降到了700左右。
6.2. 修改ab命令
思路二:apachebench的命令有问题。
修改ab命令为:ab -g t0.dat -c 1000 -t 100 -n 10000000 http://172.16.0.19/
这次,吞吐量果然上去了,变成8000左右。但是,所有实例的吞吐量都上去了!
6.3. 更换测试工具
思路三:测试工具换成webbench。
1、安装webbench
1 | wget http://soft.vpser.net/test/webbench/webbench-1.5.tar.gz |
2、测试webbench -c 10000 -t 10 http://172.16.0.19/
10s成功了80000左右的请求,说明ab测出的吞吐量是真实的。这样看来,问题还是出在apache上,吞吐量固定在8000左右。
6.4. 更换为nginx
思路四:apache更换为nginx。
1、修改apache的端口sudo vim /etc/apache2/ports.conf,端口改为8080。
2、安装nginx
1 | sudo apt install -y nginx |
3、再次测试ab -g t0.dat -c 1000 -t 100 -n 10000000 http://172.16.0.19/
吞吐量有所上升,9000左右,但是最坑的地方在于,所有实例都上升了,都是9000左右!
6.5. 提高ulimit
思路五:在实例中提高ulimit。
1 | sudo -i |
然而,吞吐量并没有变化。
6.6. 网络问题
莫非,是因为计算机网络问题?于是,在实例ubuntu0、ubuntu2、ubuntu4内部中进行ab测试,吞吐量结果为:
1 | app ubuntu0 ubuntu2 ubuntu4 |
看到这个结果,总算感觉合理了。问题也可以定位了,网络瓶颈。那么新的问题来了,不能在实例内部进行测试的情况下,怎样测试出准确的吞吐量?
6.7. 安装应用
如果能够把真实吞吐量降到8000以下,是不是就可以通过内网测出真实吞吐量了?很有可能。那么,就安装一个标准测试应用,来试试效果。找到了两款应用,mediawiki和tpcw,这里我们选择mediawiki,参考《MediaWiki安装与配置》。
安装好mediawiki后进行ab测试:
1 | ab -g t0.dat -c 10 -t 100 -n 1000000 http://172.16.0.19/mediawiki/index.php/Main_Page |
ubuntu0吞吐量为30左右,ubuntu2的吞吐量为60左右。
7. 实验流程2
假设当前只启动了ubuntu0实例,nova show ubuntu0位于compute1节点。
1、在实例中启动压力测试软件,或者在两个compute节点中启动网络故障模拟软件。(flavor实验中不需要)
2、在两个compute节点启动iptraf-ng,配置参考《虚拟机在线迁移的性能统计》。
3、在三个controller的shell中分别输入好一条命令:
1 | sudo ping 172.16.0.19 -i 0.001 >> ping.log |
然后,依次回车执行这些命令。
4、观察compute节点的iptraf-ng,等到流量不再增加,Ctrl+C结束ping命令。
5、在controller节点执行downtime.sh得到停机时间,在compute1节点执行total-time.sh得到迁移时间,在两个计算节点观察iptraf-ng得到迁移数据量。
6、等到ab命令结束,执行./format.sh t0.dat,得到吞吐量数据ff-t0.dat。
以上流程,适用于接下来的所有实验。
8. flavor实验2
1、按照实验流程,分别使用安装了mediawiki的五个flavor,进行五次迁移实验,记录实验结果。
然而,新的问题出现了,安装了mediawiki的flavor,迁移时间特别久,迁移数据量特别大,等到ab命令结束,迁移才会停止。修改ab命令为:
1 | ab -g t0.dat -t 100 -n 1000000 http://172.16.0.19/mediawiki/index.php/Main_Page |
可以成功迁移,但是另一个问题出现了,所有实例的吞吐量都下降为10左右,这日子没发过了!
是mediawiki的问题吗?创建一个index.php文件来测试一下,内容为:
1 |
|
使用ab命令测试:ab -g t0.dat -c 1000 -t 100 -n 1000000 http://172.16.0.19/index.php
ubuntu0吞吐量在800左右,ubuntu2的吞吐量在1200左右,挺不错的结果。然而,如果在ab测试时进行迁移,迁移时间依然会特别久,迁移数据量依然会特别大。ab命令停止,迁移成功停止;ab命令不停止,迁移直到失败。和mediawiki存在同样的问题。
9. 后记
实验遇到瓶颈,找叶老师商量后,决定不再适用Apache这种web服务,而是换成系统服务,比如计算任务。在实例内部运行服务记录结果,就不存在网络的影响了。